
Topic / 分区
TubeMQ的磁盘存储方案类似Kafka,在 TubeMQ 中,一个 topic 可以包含一个或者多个分区。分区分配在 Broker 节点上。
TubeMQ 的存储和 Kfaka 也是存在区别的,在 Kafka 中,一个分区对应一个可写的文件,当分区较多时,会产生较多的随机IO,使得性能急剧下降;因此 TubeMQ 在存储上相比于 Kafka 做了一些优化的设计:
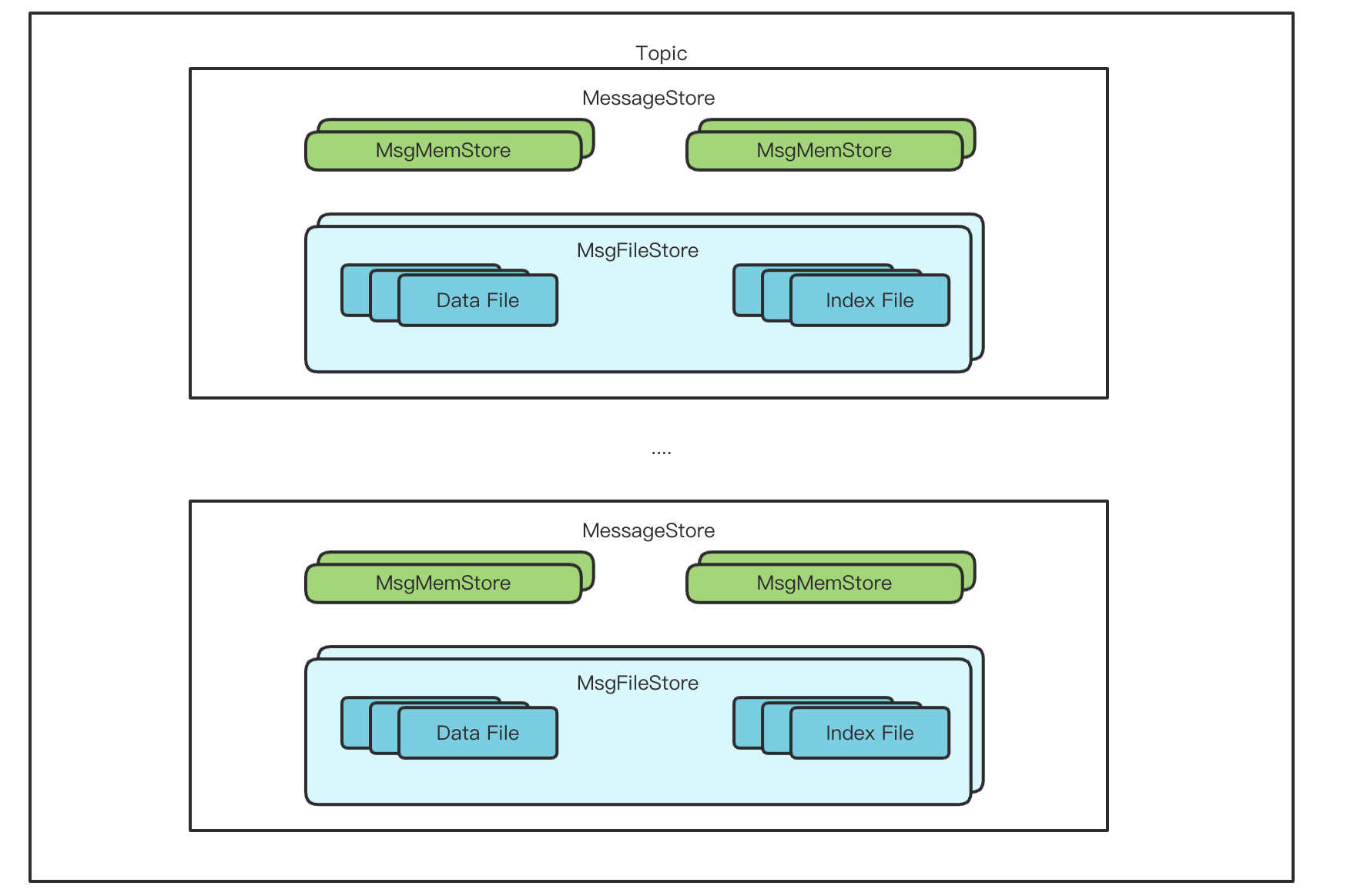
- 文件和索引不在是分区级别,而是 topic 级别,即一个 topic 在一个 broker上的多个分区会共享一个数据文件和索引文件,通过这种方式来降低分区过多时引起的随机IO问题(对应的数据结构叫 MessageStore)
- 这种方式在 topic 数量非常大时,性能也会下降,比如极端情况一个topic一个分区,就退化为何kafka类似的场景
- 还有一种场景是,一个topic在一个broker上的分区数很大,如果所有的分区数据都写入到一个文件,那么在读取一个分区数据时,可能需要遍历很多的文件,所以 TubeMQ 增加了一个限制,可以指定一定(默认是10000)的分区数共享一个数据文件;即一个topic在一个broker上可能会有多个文件写入
数据读写
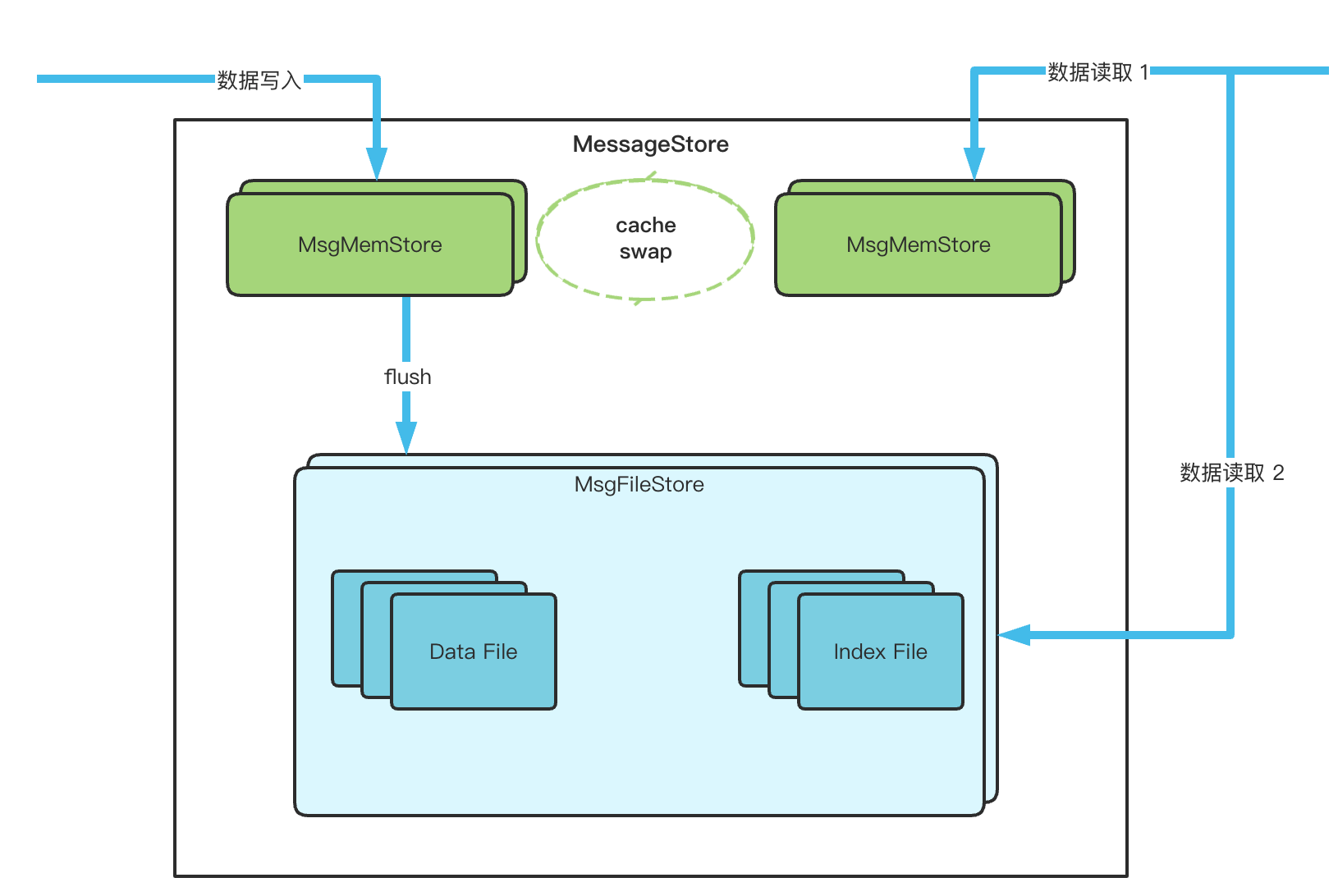
为了提升性能,实际进行数据写入和读取时,并不是直接写到磁盘的,而是先写到一块预先分配内存中,当内存写满之后,才会批量 flush 到磁盘。
在一个 MessageStore 内部,包含了两个 MsgMemStore 和 一个 MsgFileStore,MsgMemStore 可以看作一个数据的内存缓存区域,用来提升数据写入的效率,写入数据达到缓存上限(缓存消息大小、缓存消息条数和缓存索引大小都有上限)会触发批量刷盘操作,这时候另外一个 MsgMemStore 继续提供写入服务。MsgFileStore 中包含了 数据文件和索引文件,负责将数据写入到数据文件并且记录其索引位置。
MsgMemStore
MsgMemStore 使用两个 ByteBuffer 来作为 data 和 index 的缓存。写入过程如下:
- 计算 data 的 offset 信息:当前数据文件 maxOffset + cacheDataOffset
- 计算 index 的offset 信息:当前索引文件 maxOffset + cacheIndexOffset
- 将数据写入到数据缓存(bytebuffer)中
- 将索引写入到索引缓存(bytebuffer)中
- 记录每个分区和 index offset 的映射关系
cache 是有大小上限的,上限包括 数据大小、数据条数和索引大小,随着数据的写入,cache 会被写满,此时需要进行刷盘操作。
前文中有讲到内存 cache 有两个,当一个 cache 写满之后,需要进行 cache 的交换,将当前置为 toBeFlush 状态,将备用的 cache 置为主 cache。
然后开始执行 cache 的flush操作
- 获取数据缓存 bytebuffer
- 获取索引缓存 bytebuffer
- 将这两个 buffer 写入到 MsgFileStore
MsgFileStore
每个MessageStore都有一个独立的目录,对应的数据和索引文件由MsgFileStore 管理,数据文件和索引文件都是可以滚动的,所以数据文件和索引文件都有多个,每个文件都被封装成 FileSegment, MsgFileStore 有数据和索引两个 FileSegmentList,都是最后一个FileSegment可以写入。
当MsgMemStore flush 数据时,会把数据写入到磁盘,流程如下:
- 找到最后一个数据 FileSegment,写入数据(写入FileChannel)
- 如果FileSegment超过了文件大小上限(默认为1GB),把当前 fileSegment 的 flush 将数据同步到磁盘,然后创建一个新的 File 作为最后一个 FileSegment
- 找到最后一个索引 FileSegment, 写入索引信息
- 同理,超过文件大小(默认为70W个索引信息),将当前 fileSegment 索引信息flush到磁盘,然后创建一个新的 index file作为最后一个 index FileSegment
- 除了上述的在rollover文件时flush的策略之外,还有其他几个维度的控制是否执行数据的flush,满足一个就会执行flush
- 最大的un-flush消息条数
- 最大的un-flush消息大小
- 最大的un-flush时间
数据写入的大致流程就是这样,下面看下消息读取的流程,消息读取时,首先根据要读取的offset信息,判断消息是否在cache中
- 如果数据在cache
- 根据 startOffset,从Index cache 中读取到响应的数据
- 从 index 中解析出 data 对应的data cache 的offset
- 从data cache 中读取数据,返回结果
- 如果数据不在cache
- cache miss的情况下,需要从磁盘读取数据
- 首先根据offset信息,查询数据索引所在的FileSegment
- 从 索引FileSegment 中读取索引信息,根据索引获取 data offset,对应的找到对应的数据 FileSegment
- 读取数据,返回结果