
Apache Pulsar 作为新一代的Message Queue, 可以提供很多有吸引力的特性:
-
多副本
-
低延迟
-
读写分离
-
一致性
-
自动容错
-
...
这其中的很多特性都是依赖于底层存储组件 Apache BookKeeper来实现的。
Apache Pulsar 中的存储
图一展示了 Pulsar 的计算、存储分离架构,MQ的topic、分区、读写等逻辑处理都由 Broker 负责,实际的数据存储由 Bookie 节点负责,一组 Bookie 节点组成一个BookKeeper 集群。
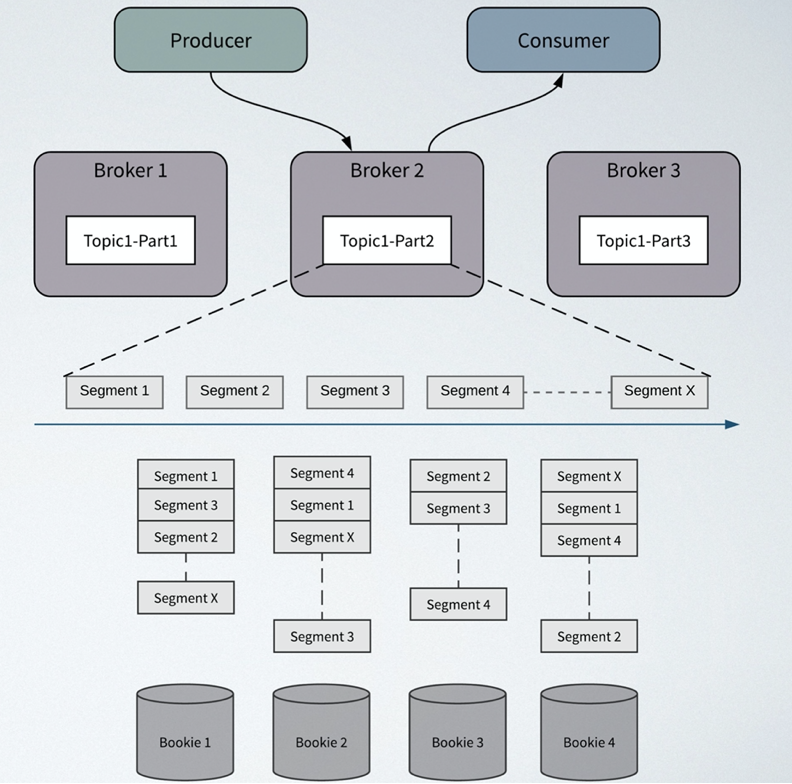
即 BookKeeper 是 Pulsar 的存储组件,对于 Pulsar 的每个 Topic(分区),其数据并不会固定的分配在某个 Bookie 上,分区数据是个逻辑上的概念,实际的物理存储会对分区数据做切片(segment),每个 segment 会保存在一个 Bookie 节点上。Topic 如果配置了副本,最终对应到存储层就是 segment 的副本数量。
BookKeeper 是什么?
BookKeeper是一个可扩展的、支持容错的、提供低延迟存储服务的分布式日志/流存储。
Apache BookKeeper 最早诞生于 Yahoo! ,作为 Zookeeper 的子项目捐献给了 ASF,在 2015 年毕业成为 Apache 顶级项目。
被用于 HDFS Write-Ahead-Log Replication、Apache Pulsar Storage Layer、HerdDB Write-Ahead-Log 等场景。
BookKeeper 架构
BookKeeper 的架构图二所示。
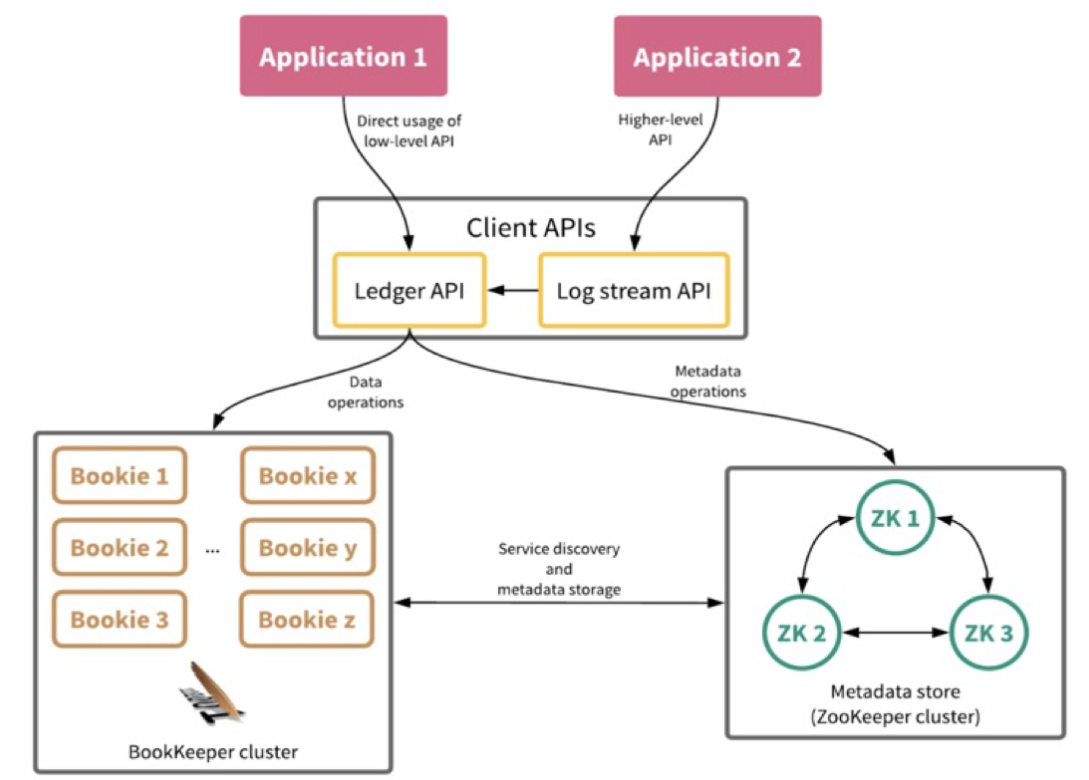
一个 BookKeeper 集群主要包括三个部分:
- Client APIs:BookKeeper 客户端,提供用于操作 BookKeeper 的 API
- Bookie cluster:由多个 bookie 节点组成,提供数据读、写和存储服务
- Metadata store:元数据存储,支持 Zookeeper 和 ETCD两种类型,主要提供元数据存储以及服务发现功能
核心概念
我们先解释一下 BooKeeper 中的核心概念。
Bookie
Bookie 是易扩展的存储server,主要提供数据的读、写服务。
ledger
Ledger 是 BookKeeper 的存储单元
-
entry的序列
-
append-only: entry 以 append-only 的方式被添加到 leger 中
-
一个 ledger同时只能有一个writer,但是可以有多个reader
-
关闭之后不可改变
Ledger 有一些元数据信息,如图三所示。

- 状态信息:标识 ledger 状态
- Last Entry Id:标识 ledger 中的最后一个 entry 的 Id
- 持久化配置:ensemble size、write quorum、ack quorum
- ensemble 列表,标识 ledger 数据存储的 Bookie 节点信息
Entry
Entry是BookKeepe的数据实体,Entry除了包含写入bookie的实际数据之外,还包含一些元数据信息,如图四所示。
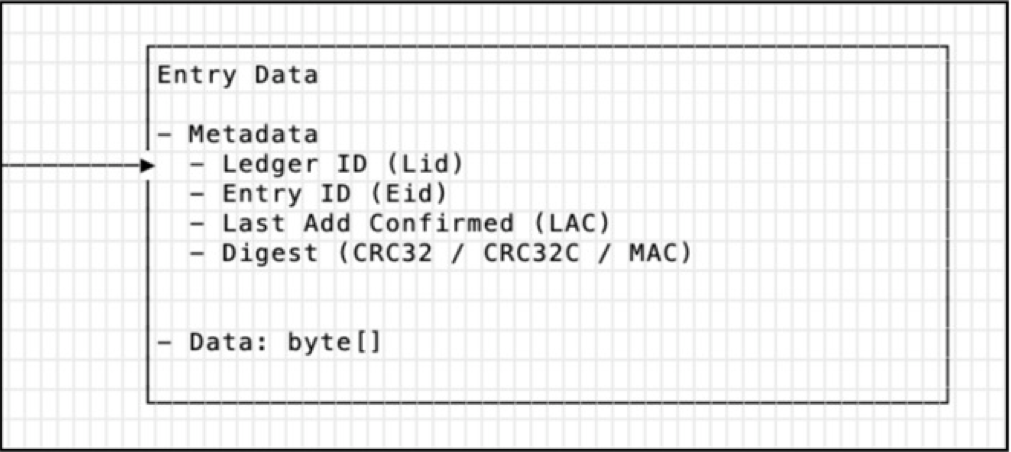
| 字段 | 说明 | 类型 |
|---|---|---|
| Ledger ID | Entry写入的ledger ID | long |
| Entry ID | Entry的唯一ID | long |
| Last confirmed (LC) | 最后记录的Entry ID | long |
| Digest | CRC校验 | -- |
| Data | 数据 | byte[] |
Pulsar 通过操作 Ledger 来完成数据的读写
- broker 接收到 producer 生产的消息之后,会对应的封装一个 Entry,然后写入 Bookie,每个 Entry 都会有一个唯一的 <LedgerId, EntryId>
- broker 通过 <LedgerId, EntryId> 来从 Bookie 读取一个 Entry,然后解析出数据推送给 消费者
Ensemble / write quorum / ack quorum
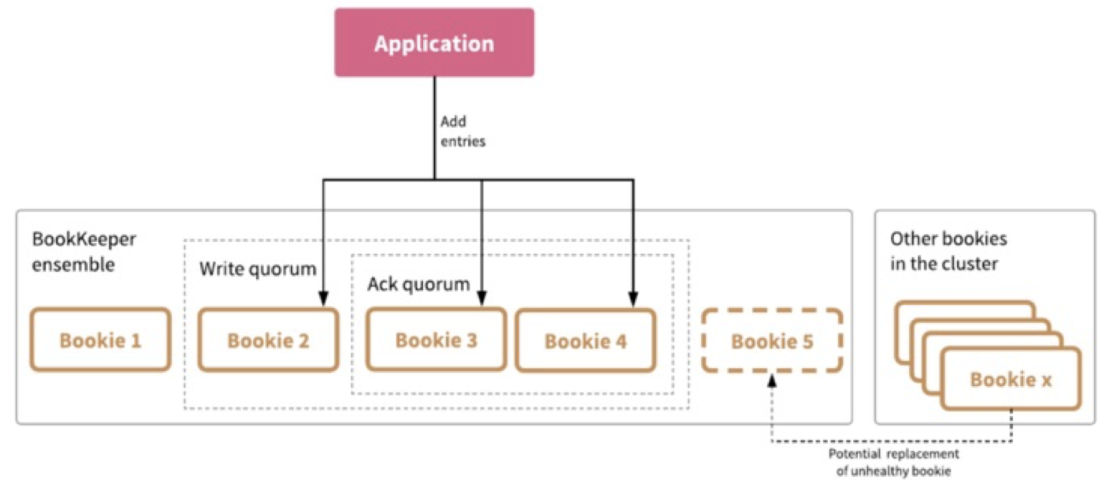
Pulsar 打开一个 Ledger 时, 需要指定三个持久化配置参数,
openLedger(ensemble size, write quorum , ack quorum ) // openLedger(5,3,2)
结合图五,三个参数含义如下:
-
ensemble size : 在初始化 Ledger 时, 首先要选取一个 Bookie 集合作为写入节点,ensemble 表示这个集合中的节点数目
-
write quorum : 数据备份数目
-
ack quorum : 响应节点数目
BookKeeper 文件组织
BookKeeper 中的文件主要包括三种,Journal、Entry Log 和 Index。
Journal
Journal 是 Bookie 的WAL 日志,主要用于 Bookie 节点重启是的数据恢复。
-
顺序 Append 的WAL 日志
-
数据持久化
-
所有的 Ledger 同时写入一个 Journal 日志文件
-
当 Journal 文件达到一定大小是会滚动生产一个新的 Journa 文件
Entry log
Entry Log 中保存了所有写入 Bookie 的数据,即 Pulsar 所有 topic 的数据最终都会保存在 Entry log中。
-
管理 Entry
-
一般是多个 Ledger 的数据聚合写入到一个 Entry log 文件中
-
当 Entry log 文件达到一定大小是会滚动生产一个新的 Journa 文件
Index file
索引文件用来保存 <LegerID, EntryID> 到 Entrylog 文件地址的映射关系,用户具体 Entry 的查找。
读写流程

数据的写入流程
-
数据首先会写入 Journal,写 Journal 的数据会实时写入磁盘以保证数据不会再重启时丢失
-
数据写入到 Memtable,Memtable 可以看做是一个读写 Cache
-
数据写入到 Memtable之后,就可以对写入请求进行响应
-
Memtable 写满之后, 数据会批量的 flush 到磁盘,同时也会将 index cache 中的 index 信息 flush 到磁盘
数据的读取流程
-
如果是 tailing read 请求(读取位置接近 Ledger 末尾的请求),直接从 Memtable 中读取 Entry
-
如果是 catch-up read 请求(读取内容不在 MemTable 中的请求)
- 读取 Index信息,找到 <ledgerId, EntryId> 对应的文件位置
- 读文件获取数据获取 Entry
BookKeeper 文件清理
Journal 和 Entry log 文件都会按照一定大小滚动,随着时间的增加,日志文件会越来越多的,因此为了避免磁盘空间被占用完,需要一种清理机制来清理文件。这里的清理包括 Journal 文件的清理和 Entry log 文件的清理。
Journal 文件清理
Journal 文件作为 WAL,保存了节点重启时需要重放的所有 Entry 信息,因此 Journal 文件的清理触发以 Entry 是否写到磁盘为界限,即如果 Entry log 中的 entry 还没有 flush 到磁盘,则对应的 Journal 文件不能被清理。
BookKeeper 使用 LastLogMark 标识最后一个 Entry 对应的 Journal 位置,LastLogMark 中保存了 JournalFileId,在 Entry log 将 Memtable 中的数据刷盘之后,那么这个 Entry 对应的 LastLogMark 之前的 JournalFile 就可以被清理。如图七所示。
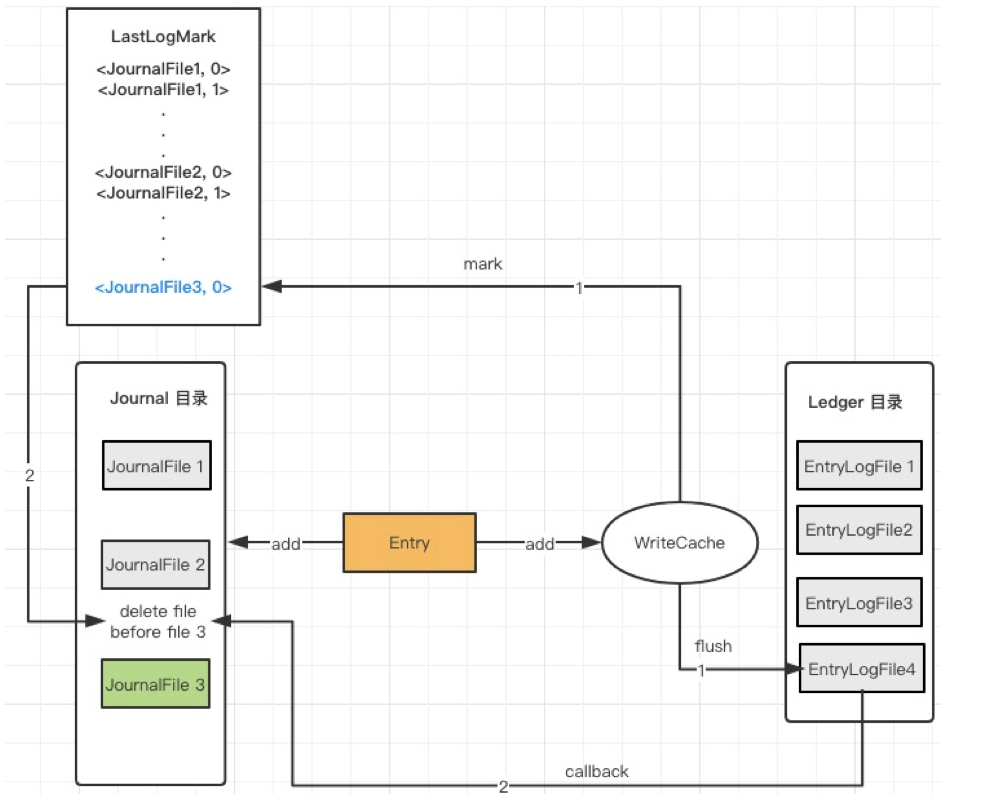
Journal 文件清理流程
-
记录 LastLogMark,WriteCache 数据flush到磁盘
-
Flush 完成之后,回调 Journal 处理
-
Journal 执行文件清理
-
获取 LastLogMark 中记录的 File ID( LJFID)
-
获取 Journal File 最大文件数配置
-
删除超过最大文件数,并且ID小于LFID的文件
Bookie 中可以配置可以保存的最大 Journal 文件数,如果文件数少于这个配置,即便是 FileId 小于 LastLogMark 中的 JournalFileId,这个 journal 文件也不会被删除。
Entry log 清理
Entry log 的清理需要有 Pulsar 处理,当Pulsar 根据配置的数据保存时间清理数据时,会删除对应的 Ledger 元数据信息,BookKeeper 的清理任务会根据 Entry log 文件的 ledger 信息,判断是否文件中的所有的 ledger 已经被删除:
- 如果 Entry log 的所有 ledger 都被删除,则 Entry log 文件可以被删除
- 否则,执行 Entry log file 压缩,压缩是为了减少已经删除 Entry 的空间占用
删除流程如图八所示。
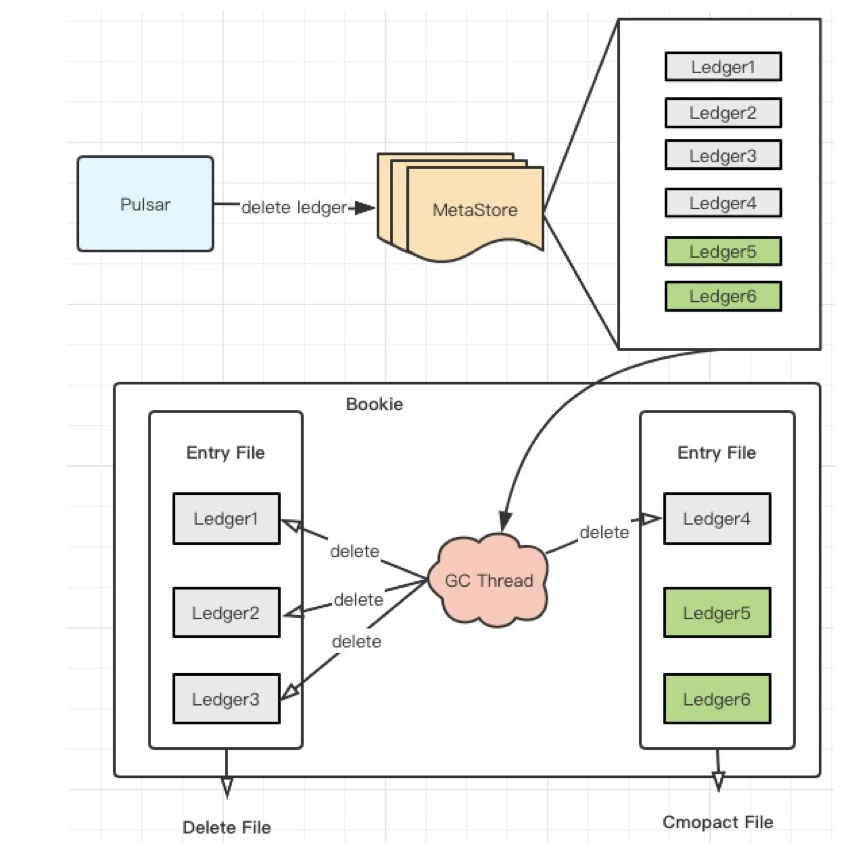
Entry 文件清理流程
-
Client(Pulsar) 从 MetaStore 中删除Ledger
-
获取 EntryFile 的元数据,主要是Ledgers信息
-
如果 Ledger 在元数据中删除,删除 EntryFile ledger信息中的相应ledger
-
如果 EntryFile 中没有ledger,删除EntryFile
-
如果 EntryFile 中有ledger, 执行压缩逻辑
Entry 文件压缩流程
-
读取 EntryLog 的内容,即读取每个 Entry
-
如果 Entry 对应的 Ledger 已经删除,跳过
-
否则,将 Entry 写入新的 EntryLog 中,更新Index信息
-
删除老的 Entry 文件
BookKeeper 核心特性
一致性
BookKeeper 的一致性主要有两个机制来保证,LAC 和 Fence,如图九所示。
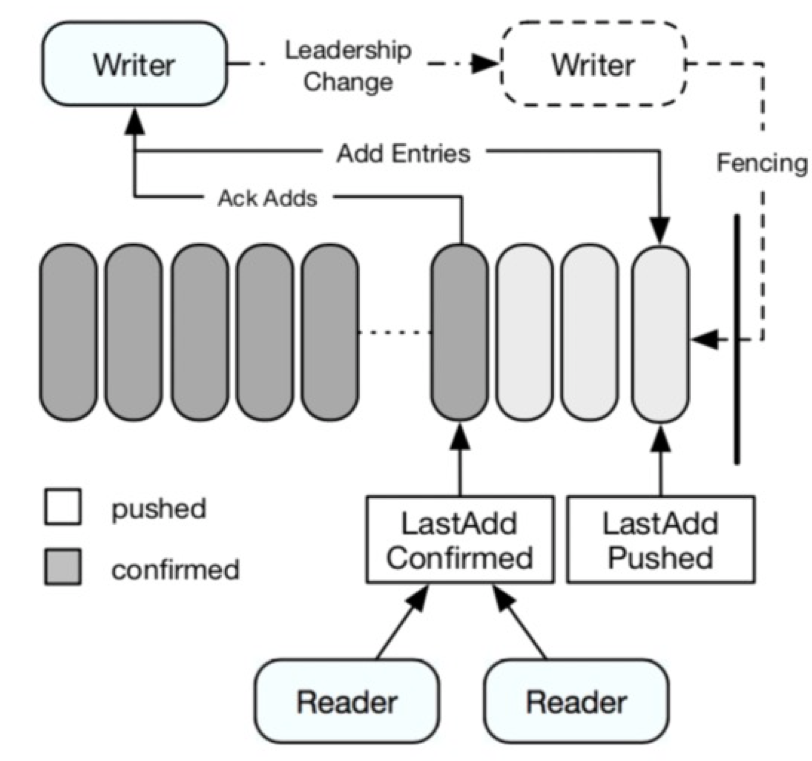
LAC
先解释一下 LAC(LastAddConfirm) 的概念,LAC 是一个 ledger 中满足 ack quorum 条件的最后一个 Entry 的 位置信息,LAC 保证有序递增。
当 客户端读取时,只能够读取 LAC 之前的数据,如 图九,Writer 可以认为是 pulsar 中的一个分区所在的 broker,即 broker 是 Ledger 的写入方, 当 broker 发其一个 addEntry 请求之后,LastAddPushed 会指向最新的 Entry 位置,当这个请求写入了 ack quorum 个 bookie 节点之后,Bookie 发送写入成功的响应给 Broker,同时更新 LastAddConfirmed,对于 Reader 来讲,只能读取到 LAC 位置,通过这种方式保证了之后满足 ack quorum 的数据才会 Reader 有可见性。
Fence机制
在 Pulsar 中,topic ownership 可能会由于重启、unload 等原因发生变更,这时 Ledger 的 Writer 也发生了变更,假设有 BrokerA 变成了 BrokerB。此时 BrokerB 成为 Ledger 的新 Writer
-
首先会检查 Ledger 的状态,如果是 Open 状态,BrokerB 会首先 fence 当前 ledger,被 fence 的 ledger 不能继续写入,通过这种功能方式保证了只有一个 Writer 可以执行写入操作
-
对 ledger 进行恢复操作,恢复到满足 ack quorum 条件的最后一个 Entry
-
新打开一个 Ledger 用于执行后续的写入操作
可用性
BookKeeper 的可用性,我们可以从写可用性和读可用性两个方面来说明。
对于写可用性,当一个 Bookie 节点故障时,BookKeeper 会从其他的可用 Bookie 节点中选取一个替换掉故障节点,替换之后组成一个新的 ensemble 信息,如图十所示。

在初始时, ensmeble 是: Bookie 1, Bookie 2, Bookie 3, Bookie 4, Bookie 5, 写入 6 个 Entry,然后 Bookie 4出现故障,此时 BookKeeper 选择了一台正常的 Bookie 6 替换了 Bookie4,此时 ensmeble 是:Bookie 1, Bookie 2, Bookie 3, Bookie 6, Bookie 5,这个过程称之为 ensemble change。变更之后的 ensemble 信息也会记录在 Ledger 的元数据中(作为 ensemble 列表的一项)。
读写分离特性
读写分离特性和实际的 Bookie 部署方式有关系,推荐将 Journal 和 Entry log 的目录配置在不同的磁盘上,并且 Journal 最好是性能更好的 SSD 类型。
前文中介绍了读写流程,可以看到在写入流程中,
-
Journal 中的数据需要实时写到磁盘
-
Entry log 的数据不需要实时落盘,通过后台线程异步批量落盘
-
写入的性能主要受到 Journal 磁盘的影响
写入过程的这种设计,在保证数据不丢失的前提下,尽可能的减小了写入延迟,提高了写入吞吐。
在读取流程中
-
Tailing read 的场景,从 MemTable 读取
-
Catch-up read 的场景,读取数据会影响 Ledger 磁盘的 IO,对 Journal 磁盘没有影响
因此,如果为 Journal 和 Entry log 配置了独立磁盘,写入和读取就不会相互干扰,从而实现读、写的分离。
AutoRecovery
在实际的运营过程中,Bookie 节点难免会出现节点宕机等异常场景,针对这种场景,BookKeeper 提供了 AutoRecovery 的能力,AutoRecovery 提供了自动恢复缺失 Bookie / Ledger 数据的能力。AutoRecovery 的过程中有两个主要的角色:
-
Auditor:负责监听 Bookie 节点存活和 Ledger 副本是否正常,并发布 rereplication 任务
-
Replication worker:执行 rereplication 任务,并完成 ledger 数据的拷贝
Auditor
Auditor 负责 Bookie 存活检查,并为出现问题的 ledger 发布 rereplication 任务,
-
监听 zk 上注册的bookie存活信息
-
如果有 bookie 宕机,扫描并找到在失败的 bookie 上存储数据的ledger
-
在/unddgerreplicated 节点下的每个ledger发布一个rereplication 任务
Replication worker 恢复流程
Replication worker 会执行 auditor 发布的 rereplication 任务,完成数据的恢复,流程如下:
-
获取 /underreplicated/ledgers 下一个ledger的恢复任务
-
遍历 ledger fragment,选出包含失败 bookie 的 fragment
-
从 ensemble 的其他 bookie 中读取 fragment 的 entry 然后写入当前 bookie
-
所有的 entry 都复制完成,更新 ensemble 信息到元数据
-
所有 fragment 复制完成之后,ledger 恢复完成
总结
Apache BookKeeper 作为 Pulsar 的底层存储组件,为 Pulsar 提供了丰富的存储特性支持,让 Pulsar 可以聚焦于 MQ 的计算逻辑,实现计算、存储分离。