
Pulsar 数据生命周期
Pulsar 作为一个 MQ,核心流程就是数据的生产和消费,对于已经写入 MQ 的数据,数据的保存和删除策略也尤为重要。
1. 背景
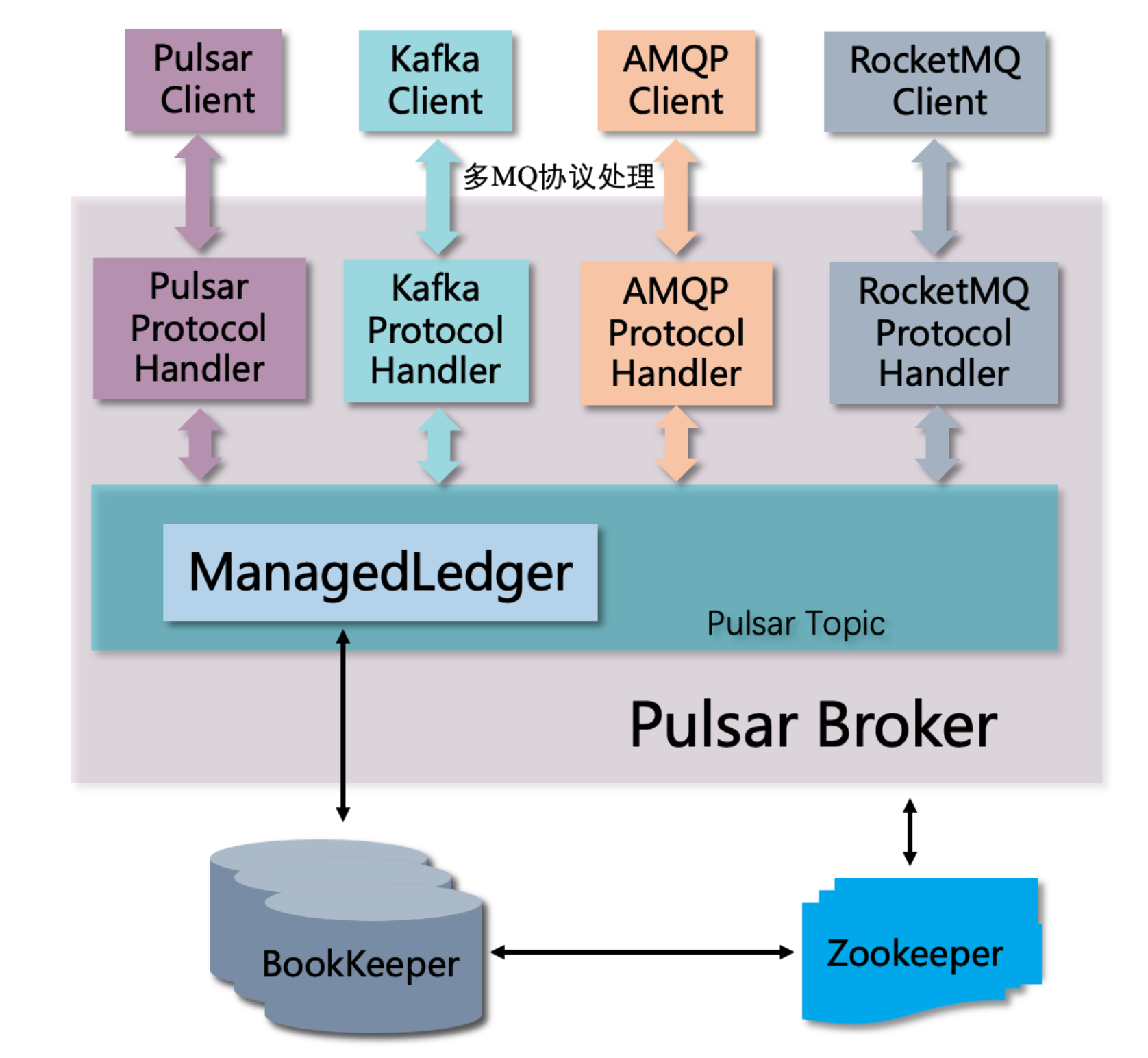
1.1 Pulsar 的组件和功能
- Broker : 提供生产/消费服务,无状态
- Bookie:存储数据,包括 Topic 中的用户数据/消费状态数据/部分系统元数据(比如 topic policy/事务状态信息等)
- ZooKeeper:元数据(Broker & Bookie)存储,服务发现
1.2 Topic/分区/ledger
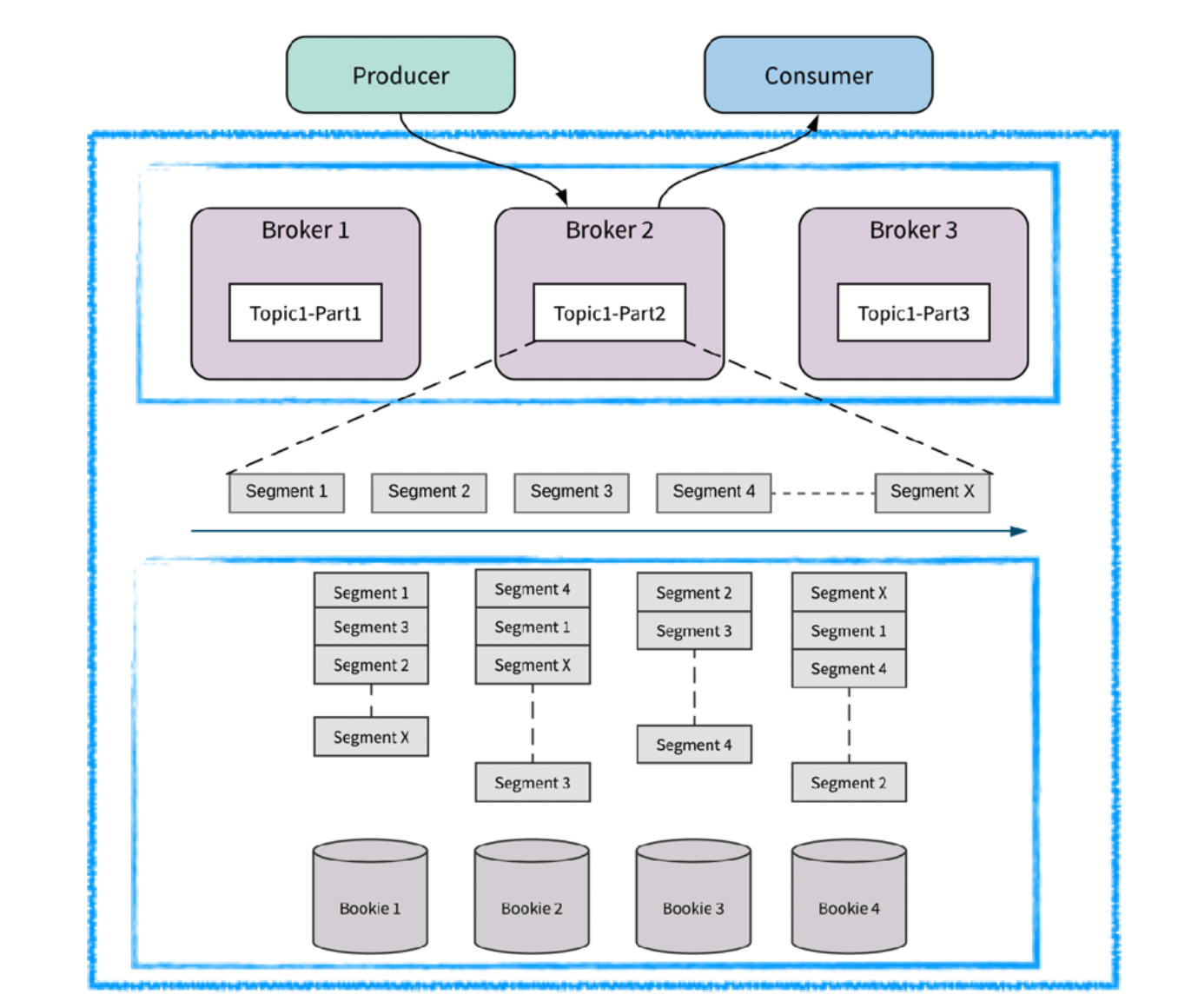
- Topic 对生产/消费提供统一的抽象
- Topic 可以包含多个分区
- 每个分区内部实际存储是 Bookie 上的物理分片,分片可以配置副本
2. 数据写入(生产)
2.1 基本概念
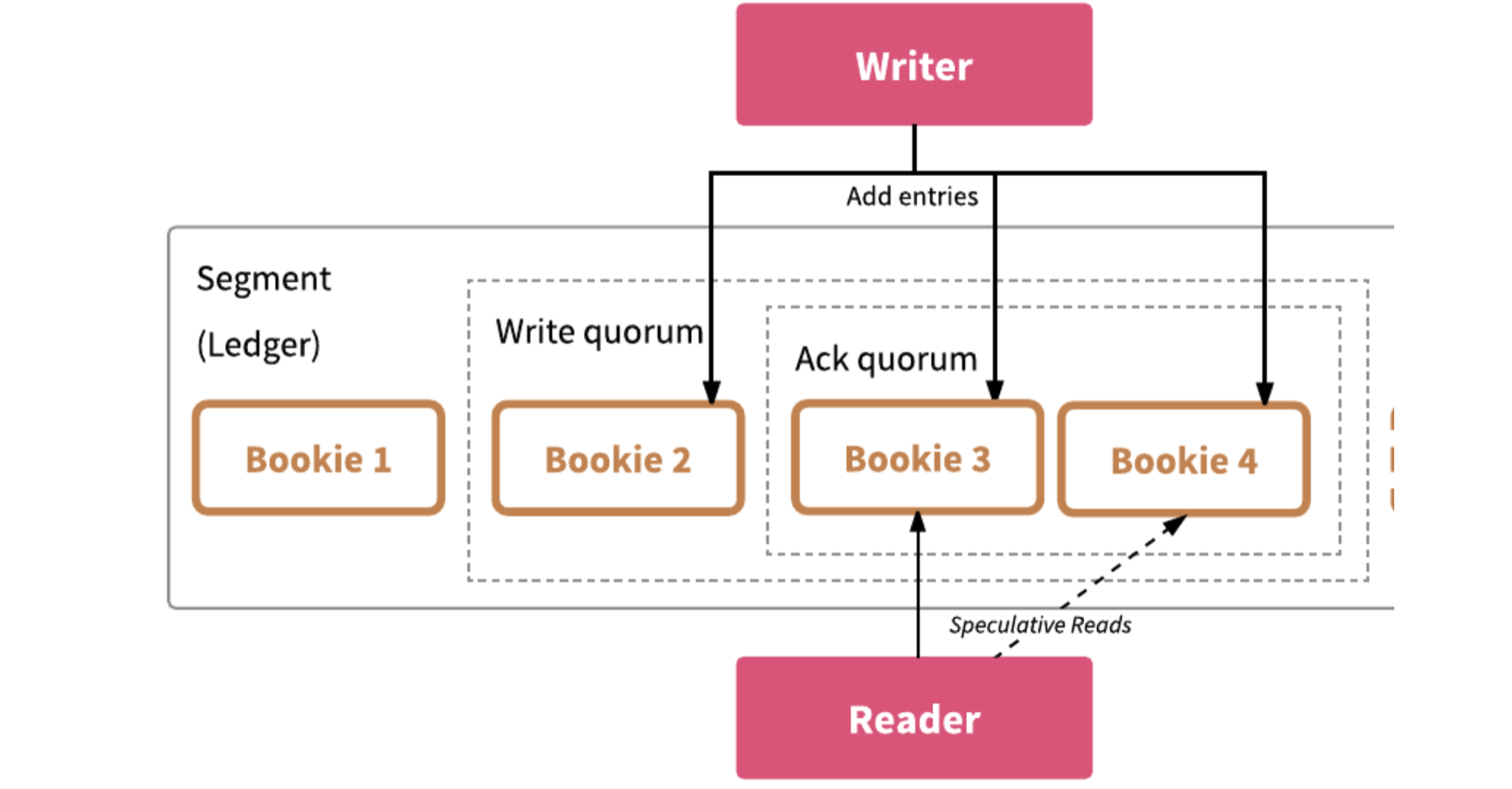
Ledger 的 核心参数:Ensemble/Write Quorum/Ack Quorum,openLedger(5,3,2)
- Ensemble :组内节点数目,
- Write Quorum: 数据备份数目
- Ack Quorum:等待响应的副本数
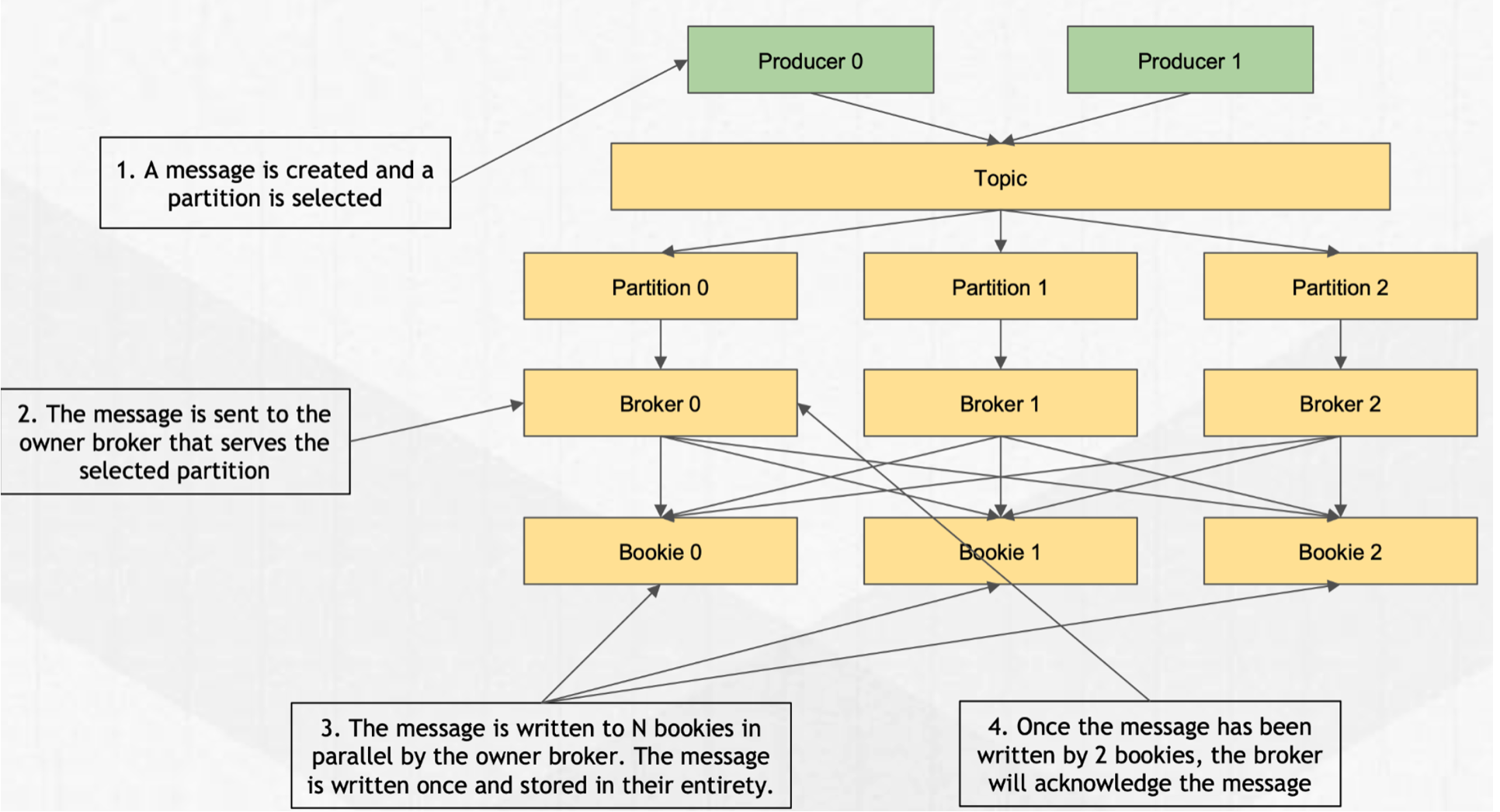
2.2 总体写入流程
- 生成消息
- 消息路由(PartitionedTopic)到具体的 Broker
- Broker 通过
ManagedLedger把数据写入到 Bookie(多副本) - Bookie 把数据写入到 EntryLogger (writeCache)和 Journal(WAL )
- Bookie 发送 response 给 Broker
- Broker 接收到大于 Ack Quorum 个相应,发送 response 给 Producer(结果包含 MessageID)
2.2.1 消息生成
消息的生成 Demo
MessageId msgId = producer
.newMessage(transaction) // 事务对象
.key("Key") // 设置 key,用于生产路由和 key_share 消费
.eventTime(System.currentTimeMillis()) // eventTime
.property("key1", "value1") // 自定义属性
.deliverAt(System.currentTimeMillis() + 1000) // 延迟消息
.replicationClusters(Arrays.asList("cluster1", "cluster2"))// GEO 指定复制集群
.value("test") // 消息内容
.send();
2.2.2 消息路由
消息路由策略在 Producer 初始化是通过 messageRouter() 接口指定。
内置路由策略包括 SinglePartitionMessageRouterImpl 和 RoundRobinPartitionMessageRouterImpl。
如果消息配置了 key,优先会按照 key hash来选择分区
if (msg.hasKey()) {
return signSafeMod(hash.makeHash(msg.getKey()), metadata.numPartitions());
}
如果消息没有 key:
- SinglePartitionMessageRouterImpl :将消息写入一个固定分区
- RoundRobinPartitionMessageRouterImpl :轮训写入所有分区
如果默认策略不能满足需求,可以自定义路由策略,实现 MessageRouter接口 :
public interface MessageRouter extends Serializable {
@Deprecated
default int choosePartition(Message<?> msg) {
throw new UnsupportedOperationException("Use #choosePartition(Message, TopicMetadata) instead");
}
default int choosePartition(Message<?> msg, TopicMetadata metadata) {
return choosePartition(msg);
}
}
2.2.3 Broker 处理数据写入
Broker 处理 TCP 协议请求的类是 ServerCnx,具体调用路径为:
ServerCnx.handleSend
=> Producer.publishMessage
=> Topic.publishMessage
=> ManagedLedger.asyncAddEntry
=> LedgerHandle.asyncAddEntry // Bk client
2.2.4 Bookie 处理数据写入
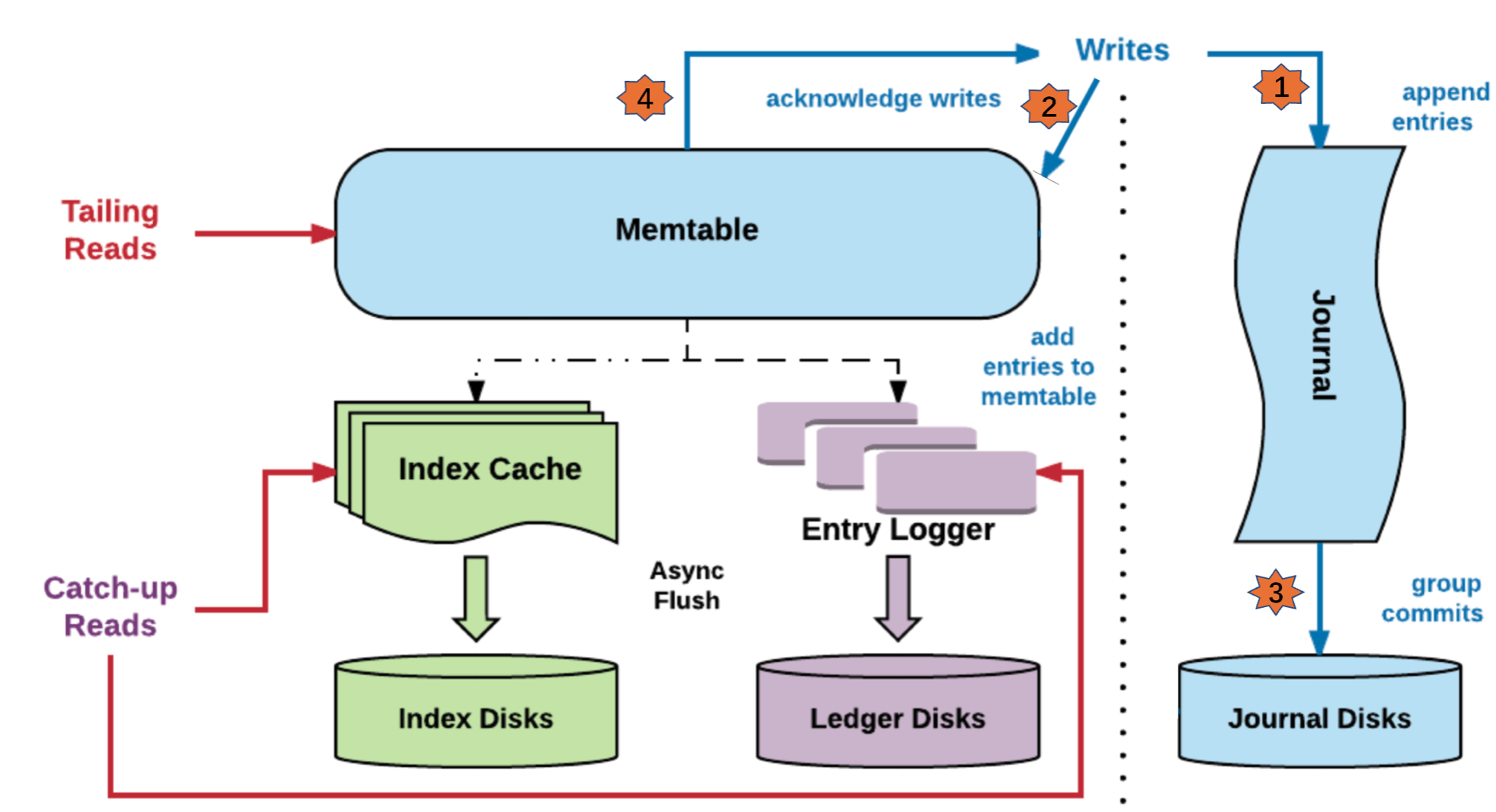
数据的写入流程
- 数据首先会写入 Journal,写 Journal 的数据会实时写入磁盘以保证数据不会再重启时丢失
- 数据写入到 Memtable,Memtable 可以看做是一个读写 Cache
- 数据写入到 Memtable之后,就可以对写入请求进行响应
- Memtable 写满之后, 数据会批量的 flush 到磁盘,同时也会将 index 信息 flush 到磁盘
2.2.5 数据写入的回调
数据写入到 Bookie 之后(ack > AQ),broker (BK-Client)认为数据写入完成,此时会将数据放入 EntryCache 中。
3. 数据读取(消费)
数据读取读取的整体流程为:
- client 发送 FLOW 请求给 Broker(携带 permit信息)
- Broker 接收到 Flow 请求之后,首先从 EntryCache 中读取
- 如果 Broker cache miss,则从 Bookie 的 writeCache 读取
- 如果 Bookie writeCache miss,则从 Bookie 的 readCache 读取
- 如果 Bookie readCache miss,则读取 index 信息,从磁盘文件读取数据
- 读取到数据之后,返回 client
- client 对消息进行 ack,确认消费完成,broker 通过
ManagedCursorImpl记录相应的 offset (<LedgerId, EntryId>)信息
4. 数据 Retention 和 TTL
数据写入到 MQ,实际上是写入到 Bookie 中进行保存的,数据的保存周期有两个配置维度: retention 和 TTL。
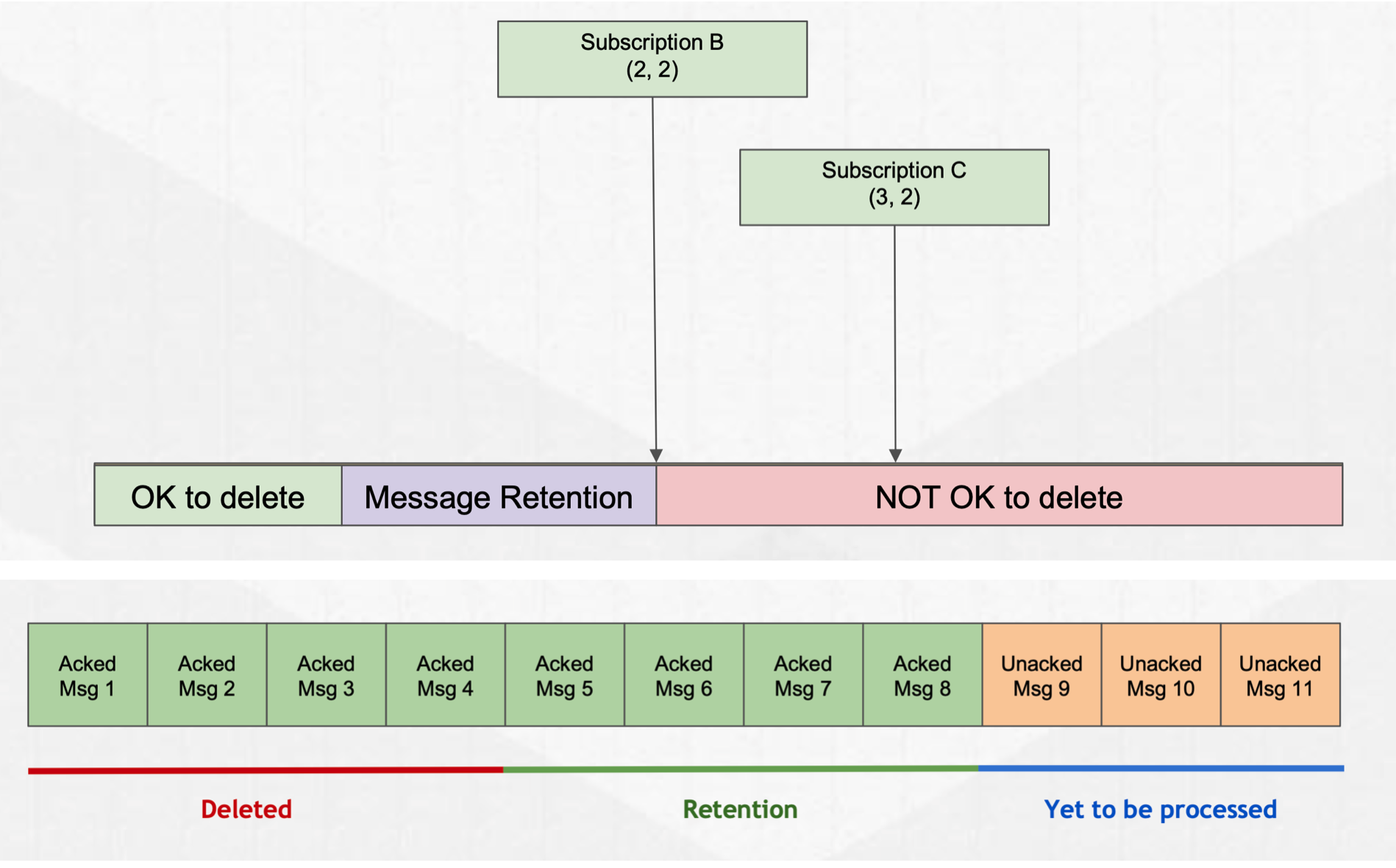
4.1 Retention
Retention 包括大小和时间,可以指定数据在订阅 ack position 之后的消息的保存时间。对于超出范围的消息会被删除。删除逻辑会在消费 ack position变动是触发,另外也会有定时任务检查数据是否可以删除。
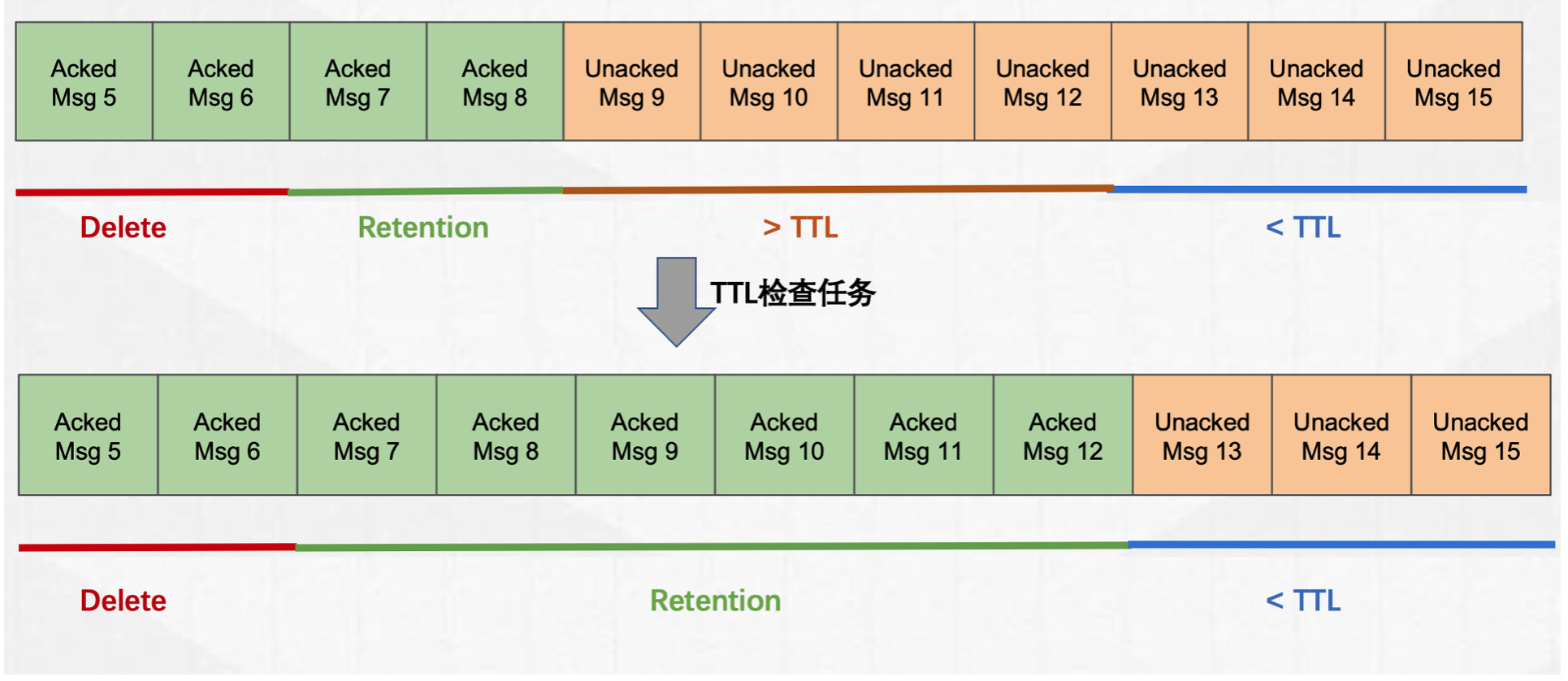
4.2 TTL
TTL 配置可以保证 topic 的消息保存超过 TTL 时间之后,所有的 cursor 的 markDelete 位置都移动到消息 publishTime 小于 TTL 的位置。
TTL 是通过定时任务来完成 cursor markDelete 位置移动的。
5. 数据删除
前文讲了 Rentention 策略会将数据删除,实际上 retention 的删除并没有真正的删除数据,而是从 Broker 侧将 Topic(分区) 元数据中对应的 ledger 删除。此时的数据依旧保存在 Bookie 上,磁盘空间不会立即被释放。
Bookie 中保存数据包括 Journal 文件 和 Entry Log 文件, Journal 和 Entry log 文件都会按照一定大小滚动,随着时间的增加,日志文件会越来越多,因此为了避免磁盘空间被占用完,需要一种清理机制来清理文件。
5.1 Journal 文件清理
Journal 文件作为 WAL,保存了节点重启时需要 replay 的所有 Entry 信息,因此 Journal 文件的清理触发以 Entry 是否写到磁盘为界限,即如果 Entry log 中的 entry 还没有 flush 到磁盘,则对应的 Journal 文件不能被清理。
BookKeeper 使用 LastLogMark 标识最后一个 Entry 对应的 Journal 位置,LastLogMark 中保存了 JournalFileId,在 Entry log 将 Memtable 中的数据刷盘之后,那么这个 Entry 对应的 LastLogMark 之前的 JournalFile 就可以被清理。

-
记录 LastLogMark,WriteCache 数据flush到磁盘
-
Flush 完成之后,回调 Journal 处理
-
Journal 执行文件清理
-
获取 LastLogMark 中记录的 Journal File ID
-
获取 Journal File 最大文件数配置
-
删除 FileId小于LFID的文件
-
Notice:Bookie 中可以配置可以保存的最大 Journal 文件数,如果文件数少于这个配置,即便是 FileId 小于 LastLogMark 中的 JournalFileId,这个 journal 文件也不会被删除。
5.2 Entry log 清理
Entry log 的清理是由 Pulsar 触发的,当Pulsar 根据配置的数据保存时间清理数据时,会删除对应的 Ledger 元数据信息,BookKeeper 的清理任务会根据 Entry log 文件的 ledger 信息,判断是否文件中的所有的 ledger 已经被删除:
- 如果 Entry log 的所有 ledger 都被删除,则 Entry log 文件可以被删除
- 否则,执行 Entry log file 压缩,压缩是为了减少已经删除 Entry 的空间占用
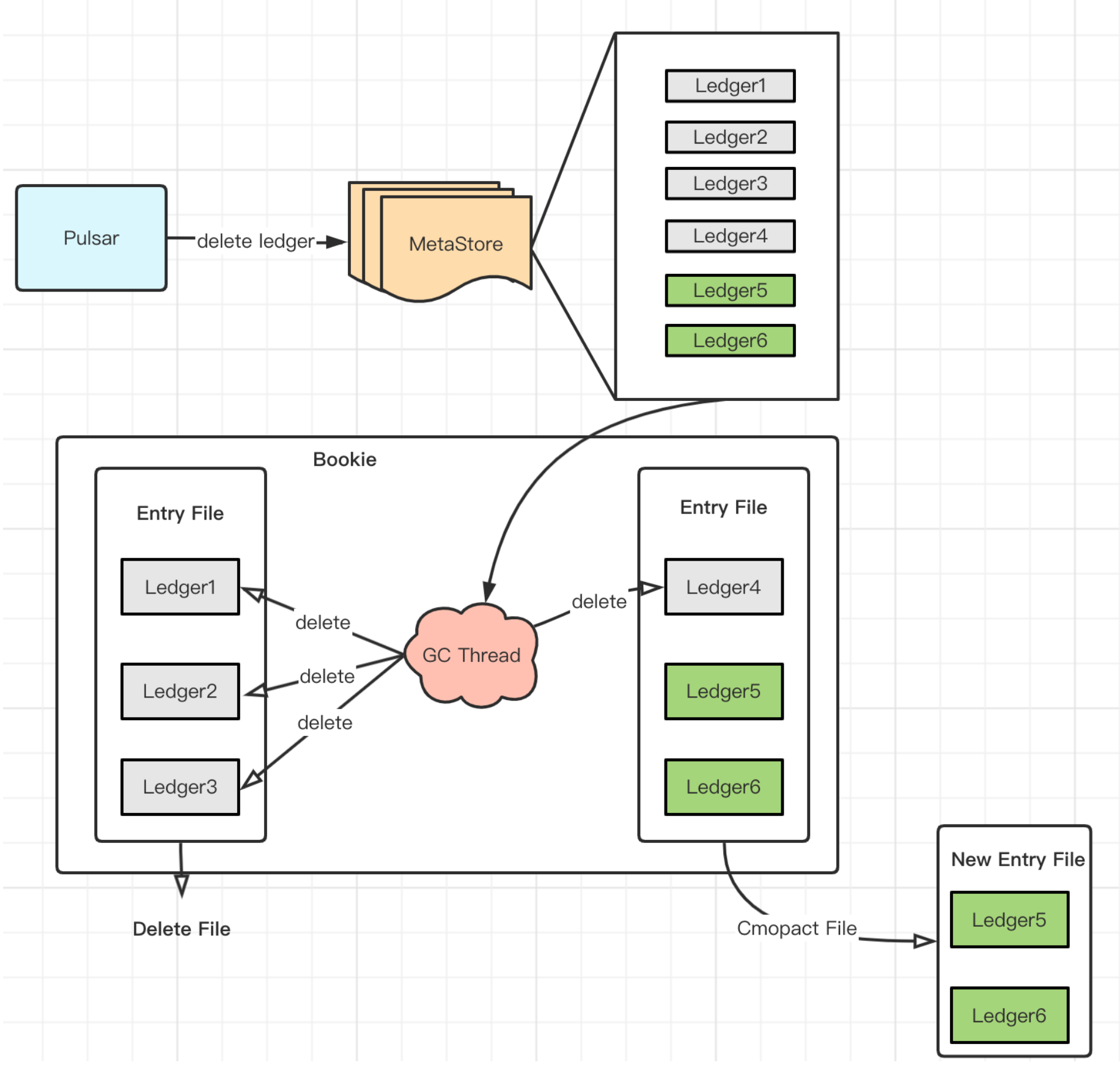
GC 检查周期默认是10分钟,每个周期会首先清理可以删除的文件,然后根据 minor gc 和 major gc 的 interval 来决定是否执行 minor 或者 major gc。
- minor gc interval 是一个小时,threshold 是 0.2(有效数据内容占比是20%)
- major gc interval 是一天,threshold 是 0.5 (有效数据内容占比 50%)
整体流程图如下:

Entry 文件清理流程
- Client(Pulsar) 从 MetaStore 中删除Ledger
- 获取 EntryFile 的元数据,主要是Ledgers信息,从 EntryFile 文件末尾的 LedgerMap 元数据读取或者遍历 EntryLog 生成,最终得到一个 EntryLog 对应的 <LedgerId, Size> 信息(ledgerMetadata)
- 如果 Ledger 在zk上被删除删除,删除 ledgerMetadata 的相应 ledger
- 如果 EntryFile 中没有ledger,删除EntryFile
- 如果 EntryFile 中有ledger, 执行压缩逻辑
Entry 文件压缩流程
- 判断threshold是否超出(区分minor和major)
- 读取 EntryLog 的内容,即读取每个 Entry
- 如果 Entry 对应的 Ledger 已经删除,跳过
- 否则,将 Entry 写入新的 EntryLog 中,更新Index信息
- 删除老的 Entry 文件