
Pulsar topic 的 schema 信息是保存在独立的 ledger 中,即在 bookie 中存储。Topic schema ledger 的元数据保存在 /schemas zk 路径下。即 Schema 的写入路径为:
- 将 Schema 信息保存在 Schema Ledger 中,并记录在 BK 中的
Position <LedgerId, EntryId> - 将 Schema 在 BK 中的存储位置记录在 zk上
Schema 的查询路径和写入路径相反:
- 先查找 Schema 元数据,获取 Schema 的存储位置
- 然后从 BK 对应位置读取得到 Schema 信息
一、Pulsar schema 服务
Broker 启动时会启动schema的存储和注册服务,
schemaStorage = createAndStartSchemaStorage();
schemaRegistryService = SchemaRegistryService.create(
schemaStorage, config.getSchemaRegistryCompatibilityCheckers());
1.1 SchemaStorage
存储服务类型由 schemaRegistryStorageClassName (默认 org.apache.pulsar.broker.service.schema.BookkeeperSchemaStorage) 决定, 默认使用 BookKeeper 作为 schema 的存储,另外,还需要奖 BK 中 Schema 数据的 Position 信息保存在 zk,这里使用到的是 LocalMetastore,路径为 $local_zk_root/schemas/tenant/namespaces/topic,注意这里的 topic 是 PartitionedTopicName(即分区 topic 也只有一个 znode 来保存 schema 元数据)。
1.2 SchemaRegistryService
在 SchemaStorage 创建完成之后创建 SchemaRegistryService,除了 SchemaStorage 之外,SchemaRegistryService 中还包含了对 Schema 进行兼容性校验的几个 checker,默认包含了一下三个 checker。
"org.apache.pulsar.broker.service.schema.JsonSchemaCompatibilityCheck"
"org.apache.pulsar.broker.service.schema.AvroSchemaCompatibilityCheck"
"org.apache.pulsar.broker.service.schema.ProtobufNativeSchemaCompatibilityCheck"
即:
JsonSchemaCompatibilityCheckAvroSchemaCompatibilityCheckProtobufNativeSchemaCompatibilityCheck
在三个checker每个都有自己的SchemaType,会保存在 <SchemaType,Checker> 类型的map中。除了这三种类型之外, checkers map 中好保存 KEY_VALUE类型对应的 checker。
注意:KV 类型的 Schema 信息,分别对于 key 和 value 做兼容性校验。
二、schema 信息保存
Schema 信息可以在 client 创建 producer 或者 subscription 时保存
- Producer:如果 producer 携带了 Schema 信息,则保存 schema
- Subscription:如果 topic 已经有 schema,则进行兼容性校验;如果没有,则保存 schema
以 Producer 为例来描述 Schema 保存的流程,兼容的逻辑单独来讲。
如果客户端 Producer 配置了 Schema 信息,当 Broker 接收到 Producer 请求时,会尝试将 Schema 信息保存。
整个流程图如下:
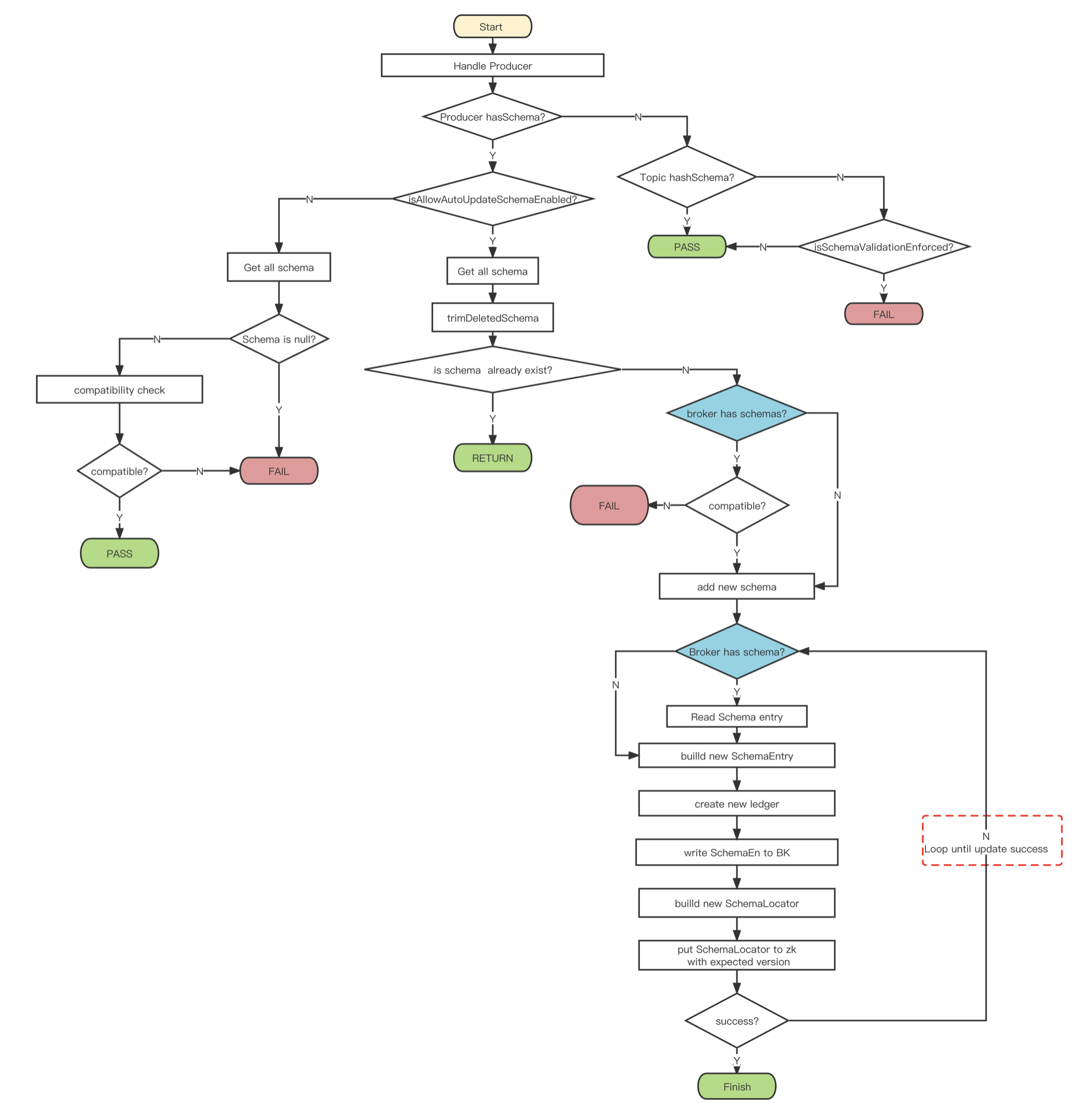 

2.1 Producer 携带 schema 的链接
如果 Producer 是携带了 Schema 信息,则尝试将 Schema 记录下来。
首先判断是否支持 schema 的自动更新,isAllowAutoUpdateSchemaEnabled。
2.1.1 允许自动更新
首先 读取已有的所有 schema 信息,分为两个步骤:
- 从 zk 读取 schema 元数据,元数据中保存了 schema 信息保存的存储位置,元数据信息 SchemaLocator 的内容如下:
message SchemaLocator {
required IndexEntry info = 1; // 最新信息
repeated IndexEntry index = 2; // 历史信息
}
- 如果 locator 为空,说明没有 schema 信息,返回;如果有 locator,遍历 index 中的所有 schema 信息,返回;
如果在读取 schema 的过程中出现了异常,如果可恢复的异常(非 SchemaException 或者 是 recoverable 的 SchemaException),直接返回结果;否则,执行 schema 的强制删除逻辑,删除所有 schema 所在的 ledger 和 znode。
**然后 **开始处理 schema 信息,这里的处理就是从读取的所有 schema 中过滤已经被标记删除的 schema 信息。这里解释一下,schema 的删除不会直接删除历史 schema 信息,而是创建了一个 新的 SchemaEntry,并且携带了 deleted 标记。
经过上面两个步骤,获取到的是有效的 schema 信息(可能为空)。
**接下来 **要把 producer 的 schema 和历史 schema比较,查看 schema 是否已经存在,如果存在则返回对应的历史 schema 的 SchemaVersion 信息,流程结束。如果没有历史 schema 或者没有匹配的历史 schema,说明 producer 携带的是一个新的 schema 信息。
**最后 **看一下新 schema 的处理流程,先对 schema 进行兼容性检查,根据不同的 SchemaCompatibilityStrategy 执行不同的检测,不兼容会抛出异常:
- ALWAYS_COMPATIBLE:直接返回
- FORWARD_TRANSITIVE/BACKWARD_TRANSITIVE/FULL_TRANSITIVE 检查所有版本是否兼容
- 其他:检验最新版本的 schema 是否兼容
兼容性检查通过说明 schema 可以被持久化,写到 Bookie 上的 Schema 对象是 SchemaEntry,
message SchemaEntry {
required bytes schema_data = 2;
repeated IndexEntry index = 5;
}
message IndexEntry {
required int64 version = 1;
required PositionInfo position = 2;
required bytes hash = 3;
}
message PositionInfo {
required int64 ledgerId = 1;
required int64 entryId = 2;
}
写入之前会再次判断是否存在 schema(可能在这个过程中间有其他broker已经写入了 schema信息),判断逻辑是 zk 路径上是有保存了 SchemaLocator 信息
-
1 如果有 SchemaLocator,
- 首先读取 Schema 信息,读取 SchemaLocator Index 信息中的第一个位置(读取内容没用上,估计是为了验证bk上确实有存储)
- 构建新的 SchemaEntry
- 其中 schema_data 保存了 schema 的二进制内容
- IndexEntry 列表的内容为 SchemaLocator 的 Index 列表,即最新的 Schema 信息中包含了所有历史 Schema 的 IndexEntry 信息
- 创建一个新的 Ledger ,并把 SchemaEntry 写入到这个 Ledger,并获取写入的位置 position
- 构建新的 SchemaLocator
- Info 信息:version 为当前 Locator version +1,positioin 为最新的 Schema 的保存位置,hash 为最新 schema_data 的hash
- Index 信息:当前 Locator的 Index Entry 列表,加上 Info 信息(位于 列表尾部)
- 将 SchemaLocator 写入zk,写入是 expectedVersion 为就 Locator 的版本,如果在此之前已经有其他分区或者 broker 在已经写入了 SchemaLocator,则版本不一致,此次更新会失败,然后会重试,重试逻辑和写入逻辑完全一样,重试时,可以确认 schema 已经存在,然后跳转到1进行处理(这里会造成 zk 的反复读写)
-
2 如果没有 SchemaLocator,则认为是新增 schema(实际上还是有可能冲突)
- 构建一个新的 SchemaEntry
- 其中 schema_data 保存了 schema 的二进制内容
- IndexEntry列表 只包含一个新的 IndexEntry(version 为 0, hash 为 schema_data 的 hash 值,position 为 -1:-1)
- 创建一个新的 Ledger ,并把 SchemaEntry 写入到这个 Ledger,并获取写入的位置 position
- 然后构建 SchemaLocator
- 构建出 info 信息(version 为 0,position 为 schema 保存的 position,hash 是 schema_data 的 hash值)
- 构建 index 信息,首次创建,没有历史信息,index 长度为1,内容就是 info
- 将 SchemaLocator 写入zk,写入是 expectedVersion 为 -1,表示是首次写入,如果在此之前已经有其他分区或者 broker 在已经写入了 SchemaLocator,此次更新会失败,然后会重试,重试逻辑和写入逻辑完全一样,重试时,可以确认 schema 已经存在,然后跳转到1进行处理(这里会造成 zk 的反复读写)
- 构建一个新的 SchemaEntry
2.1.2 不允许自动更新
如果不允许自动更新,则查找现有的 Schema 中是否有何 Producer 的 schema 匹配的 Schema
- 读取 zk 获取 SchemaLocator
- 遍历 SchemaLocator 的 index 列表,读取所有 Schema 信息
- 遍历 Schema 信息 和 producer schema 匹配
- 匹配失败返回异常(如果不存在 Schema 也返回异常)
2.2 Producer 不携带 schema 的链接
判断 topic 是否具有 schema 信息,首先读取 zk 上的 schema 元数据,然后读取最新版本的 schema 数据。如果 zk 上没有元数据,或者 bk 上没有 schema 信息,都表示没有 schema 信息。
- topic 没有schema:校验通过
- topic 有 schema:此时需要判断是否开启强制校验,
isSchemaValidationEnforced,如果为 true,说明需要强制校验,则返回IncompatibleSchemaException
2.3 Consumer 携带 Schema的链接
如果 consumer 携带了 Schema,那么需要对 schema 进行兼容性校验或者新增 schema,需要进行 Schema验证的场景包括:
- topic 具有 schema
- topic 的 producers 不为空
- topic 有存活的 consumer
- topic 已经有数据写入
兼容检查的逻辑如下:
- 读取 schema 信息,如果 schema 存在且没有被删除,则根据兼容性策略执行校验
- 如果策略是 BACKWARD、FORWARD、FORWARD_TRANSITIVE 或者 FULL,对最新的 schema 信息进行兼容性检查
- 其他策略,对所有历史 schema 执行兼容性检查
如果没有schema 信息则执行 schema 的新增,类似 producer,不再赘述。