
[toc]
1. Pulsar 事务介绍
在 pulsar 中可以通过 produce 异常重试、consume 异常不 ack 的方式保证数据的不丢失,即 atleast-once 语义;
Pulsar 提供了一个幂等(idempotent)producer 的特性,可以从 broker 侧对数据进行去重,但是幂等 producer 会有限制,只能保证单个 porducer 链接在单分区上的去重:
- 不能保证多个消息的原子性
- 不支持分区topic的去重
Pulsar 的事务增强了 Pulsar 的消息投递语义,可以支持多个 topic的原子写入和ack,pulsar事务允许:
- 生产者可以向多个topic生产一批数据,这批数据要么全部对consume可见,要么全部不可见(pulsar 只有一个默认的隔离级别,read-commit)
- 端到端的 exactly-once 语义,即consumer-process-produce操作的exactly-once
1.1 Pulsar 事务语义
- 事务中的所有操作是一个原子单元
- 所有的消息都会提交,或者都不提交
- 每个消息都会被处理一次,不会有丢失和重复
- 如果事务 abort,那么事务中的写入和 acks 都会回滚(事务操作设计两个部分,一个是生产,一个是消费)
- 一组消息可以从多个分区中接受、处理、并且写入到多个分区
- consumer 只能读取 commit 的消息,如果事务正在进行中或者已经丢弃,那么该事务产生的消息不会对consumer可见
- 可以跨多个分区写入数据
- 订阅的 acks 是原子性的
1.2 事务和流处理
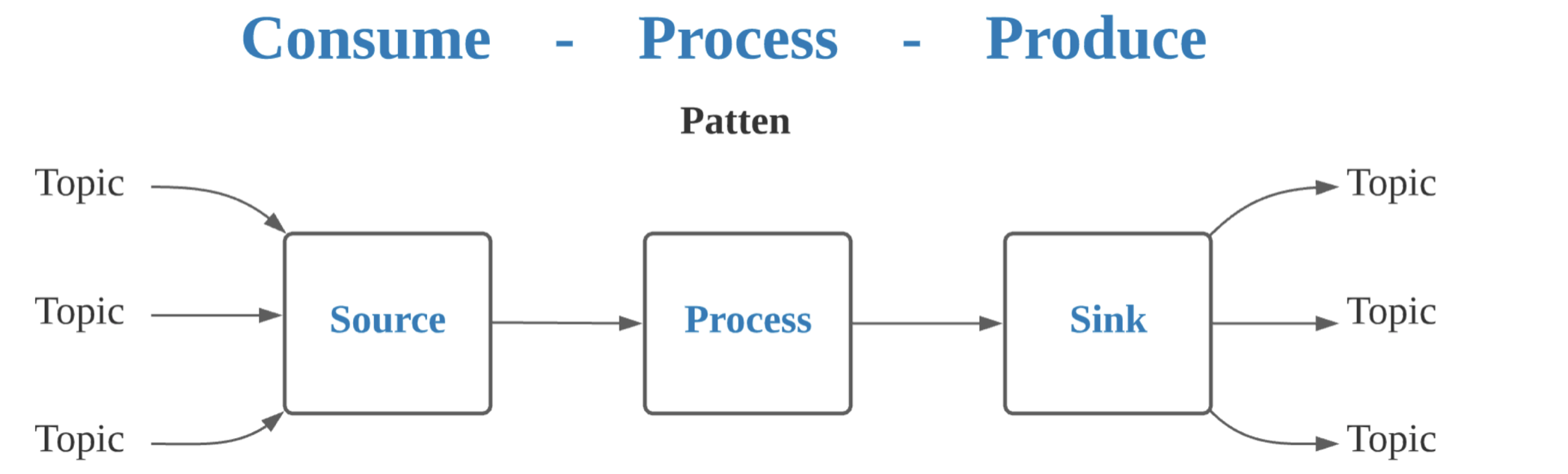
pulsar 中的 stream processing 是指一个 consume-process-produce 的过程:
- 消费:从一个或者多个 topic 消费的算子,包含 pulsar 的消费者
- 处理:消息处理
- 生产:将结果消息写入到一个或者多个 pulsar topic 的中
2. Pulsar 事务原理
2.1 关键概念
-
Transaction coordinator:TC,运行在 broker 上的一个 Module, TC 对应的 topic 是全局级别的。
- 维护事务的整个生命周期保证事务状态的正确性
- 处理事务超时,保证事务超时之后会被丢弃
-
Transaction Log:所有的事务元数据都会持久化在 transaction log中(实际是一个 pulsar 的 topic),TC 崩溃时,可以从 transaction log 中恢复,transaction log 中记录的是事务的状态额不是实际的消息(message 还是保存在 topic partition中)
-
Transaction Buffer:TB,在一个事务中写入一个分区的多条消息保存在 TB 中(即每个分区都有一个 TB),在 TB 中的消息对 consumer 不可见(直到事务 commit 才可见,事务 abort 时会被丢弃);TB 中保存了所有正在进行和已经丢去的事务。所有的消息都写入到了实际的 pulsar topic 分区,当事务提交之后, TB 中的消息会物化 (对 consumer 可见),当事务 abort 时,TB 中的消息会被删除。(这里只是逻辑上这样讲,实际处理参考后续的分析)
-
Transaction ID:事务ID (TnxID),定义了一个唯一的事务,TransactionID 是一个 128 位,高 16 位保存 TC 信息,剩余的部分用来保存一个 TC 内部单调递增的数字。
-
Penging acknowledge state : pending ack stats 维护了事务提交之前的所有的 message ack 信息,如果一个消息处于 pending ack stats 中,那么其他的事务不能 ack 这个消息(直到 这个消息从 pending ack stats中移除),pending ack state 信息会被持久化到 ack log中(实际上是 cursor ledger)。
2.2 事务准备
2.2.1 客户端事务准备
可以看到整个事务的协调者称之为 TC,TC 在 broker 上提供服务,TC 可以为 客户端分配事务、管理事务状态等元数据信息。
使用事务,需要在创建 Client 时,对事务进行 enable。
pulsarClient = PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650")
.statsInterval(0, TimeUnit.SECONDS)
.enableTransaction(true) // enable 事务
.build();
客户端使用事务需要和 TC 进行交互,这里的交互是通过 TransactionCoordinatorClientImpl 来实现的,如果 client 开启了事务特性,那么在初始化 build 时,会初始化一个 TransactionCoordinatorClientImpl 并启动。
我们来看一下
TransactionCoordinatorClientImpl的启动过程:首先,查询 topic
pulsar/system/transaction_coordinator_assign的 分区元数据,这个 topic 在集群搭建时会创建,默认是 16 个分区,也可以通过一下命令来创建。bin/pulsar initialize-transaction-coordinator-metadata -cs 127.0.0.1:2181 # configuration store address -c $cluster_name # cluster name --initial-num-transaction-coordinators 16 # tc 数量,即 tc topic 的分区数注意:
pulsar/system/transaction_coordinator_assign这个 topic 就可以理解为 Pulsar 用来模拟 TC,TC 有多个,每个分区表示一个 TC,分区的 index 就是 TC 的 ID。然后,对每个分区都创建一个
TransactionMetaStoreHandler,TransactionMetaStoreHandler 中记录了 TC 的 topic、tcId,TransactionMetaStoreHandler 还可以处理事务请求(包含四种类型:newTxn 请求、addPublishPartition 请求、addSubscription 请求和 endTxn 请求)的超时,请求超时时间是 client 配置的operationTimeoutMs, 默认是 30s。另外,
TransactionMetaStoreHandler对应于 TC topic 的一个分区,因此需要单独创建到 TC 的链接,所以有自己的 connectionHandler 来管理与 TC 的链接,每个 TransactionMetaStoreHandler 都有一个 connectionFuture 表示和 TC 的链接是否完成。接下来,会启动
TransactionMetaStoreHandler第一步: lookup TC 分区,并且创建(物理)链接的过程(lookupservice 就是 pulsarClient 的 lookupService,和 prouducer/consumer 一样),建立连接之后才可以继续执行事务的操作
第二步:链接创建完成会回调 TransactionMetaStoreHandler#connectionOpened,然后向 TC 发送
TcClientConnectRequest, 请求内容包含 TCID 和 RequestId第三步:接收到 TC 的响应之后,
TransactionMetaStoreHandler状态修改为 Ready,记录 TCID 和TransactionMetaStoreHandler的映射关系,connectionFuture 完成,处理 pending 的事务请求(如果有的话)。如果只是从和 broker 的交互上来看,TransactionMetaStoreHandler 和 producer (或者 consumer )比较类似,都是会创建到对应分区的链接(会获得一个 ClientCnx 对象),并且在 clientCnx 中记录<TCID, TransactionMetaStoreHandler> 的映射关系,事务请求就是向 TC 分区发送消息(类似于生产者像一个分区发消息)
再看下 TC 的处理,这里 client 向 TC 发送的是一个 TcClientConnectRequest 请求。
2.2.2 Broker 事务准备--事务元数据
对于客户端的 TCClientConnect 请求,Broker 通过 TransactionMetadataStoreService 来处理(所有的事务操作都会通过 TransactionMetadataStoreService 来记录)。
开启事务需要在 broker.conf 中修改以下配置:
//mandatory configuration, used to enable transaction coordinator
transactionCoordinatorEnabled=true
//mandtory configuration, used to create systemTopic used for transaction buffer snapshot
systemTopicEnabled=true
//if you want to acknowledge batch messages in transactions,
acknowledgmentAtBatchIndexLevelEnabled=true
TransactionMetadataStoreService 在 Broker 服务启动时创建:
transactionMetadataStoreService = new TransactionMetadataStoreService(TransactionMetadataStoreProvider
.newProvider(config.getTransactionMetadataStoreProviderClassName()), this,
transactionBufferClient, transactionTimer);
TransactionMetadataStoreService 中包含一个
TransactionMetadataStoreProvider, 支持自定义,目前有两种实现:
- InMemTransactionMetadataStoreProvider:使用内存记录事务元数据
- MLTransactionMetadataStoreProvider:使用 ManagedLedger(BK)记录事务元数据
默认是MLTransactionMetadataStoreProvider 用来创建 TransactionMetadataStore, TransactionMetadataStore 也有两种实现
- InMemTransactionMetadataStore
- MLTransactionMetadataStore
TransactionMetadataStore 和 provider 的类型对应,默认是 MLTransactionMetadataStore,处理事务元数据的更新、恢复等。
在 TransactionMetadataStoreService 中
Map<TransactionCoordinatorID, TransactionMetadataStore> stores保存了 TCID 和 TransactionMetadataStore 的映射关系,即每个 TC 都有自己对应的 TransactionMetadataStore。TransactionMetadataStoreService 还包含一个
TransactionBufferClient,作用是在结束事务时,向事务涉及的所有分区和订阅发送 commit 或者 abort 的信号(这个名字有一些歧义,和生产者事务中的 TransactionBuffer 不一样,关注其作用即可),TransactionBufferClient 中会创建一个TransactionBufferHandler用来实际执行结束事务的操作,在结束事务时,需要向事务中注册的所有分区发送消息,因此需要建立到分区的链接,然后发送请求。总结,TransactionMetadataStoreService 通过
- TransactionMetadataStore 来保存事务元数据
- TransactionBufferClient (内部实际是 TransactionBufferHandler)来处理事务结束。
注意:TransactionMetadataStoreService 在每个 Broker 上都会创建(前提是 Broker enable trasaction),但是实际起作用的只有 TC 分区所在的 broker,其他的 Broker 并不会接收到事务操作请求。
当 Broker 接收到 TcClientConnect 请求时,会使用 transactionMetadataStoreService#handleTcClientConnect来处理,首先会校验 TC 分区pulsar/system/transaction_coordinator_assign-partition-$TCID是否在当前 broker 上,然后延迟创建 TCID 对应的 TransactionMetadataStore(使用 MLTransactionMetadataStoreProvider#OpenStore)。
TransactionMetadataStore 也是通过 ManagedLedger 来保存数据的,类似于 topic 或者分区。
2.2.2.1 TransactionMetadataStore 的初始化
TransactionMetadataStore 中包了几个关键组件:
2.2.2.1.1 MLTransactionSequenceIdGenerator
可以通过 AtomiLong 来产生一个递增的事务ID,并且保存了当前最大的事务ID(sequenceId);另外还继承了 ManagedLedgerInterceptor,Interceptor 的主要目的是为了记录和恢复历史最大的事务ID,注意这里的拦截是 TransactionMetadataStore 自己对应的 ML
- 在 ML properties 初始化时拦截,从属性里获取
MAX_LOCAL_TXN_ID,用来恢复最大的事务ID - 在 ML 最后一个 Ledger 初始化完成时拦截,从最后一个 Ledger 中读取 Entry,来恢复最大的事务ID
- 在 ML 中 ledger 滚动时(包括初始化创建新 Ledger),向 ML 的属性中写入最大的事务ID
2.2.2.1.2 MLTransactionLogImpl
MLTransactionLogImpl是 TransactionLog 基于 ML 的实现,ML name 是 pulsar/system/__transaction_log_$TCID, 这个 ML 就是实际保存事务元数据的,每个 TC 都有一个 MLTransactionLogImpl。
MLTransactionLogImpl 创建之后会进行初始化:
- 首先创建一个 ML,name 是
pulsar/system/__transaction_log_$TCID - 创建一个
TxnLogBufferedWriter,用于支持 ML 的批量写 - 为 ML 创建一个 ManagedCursor,用于读取 ML 的数据,cursor 名字是
transaction.subscription, cursor 其实位置为 earliest
TxnLogBufferedWriter 提供了批量写 TxnLog ML 的能力,默认是不开启的;batch 提供了三个限制维度,entry 数、大小和时间;
final TxnLogBufferedWriterConfig writerConfig = new TxnLogBufferedWriterConfig(); writerConfig.setBatchEnabled(serviceConfiguration.isTransactionLogBatchedWriteEnabled()); // 默认是 false writerConfig.setBatchedWriteMaxRecords(serviceConfiguration.getTransactionLogBatchedWriteMaxRecords()); writerConfig.setBatchedWriteMaxSize(serviceConfiguration.getTransactionLogBatchedWriteMaxSize()); writerConfig .setBatchedWriteMaxDelayInMillis(serviceConfiguration.getTransactionLogBatchedWriteMaxDelayInMillis());如果 batch 开启,当写入数据是就是直接
managedLedger.asyncAddEntry来写入;如果开启了 batch
- 首先在
TxnLogBufferedWriter创建时,就会初始化一个超时任务,用来触发 batch 数据的写入- 在写一个数据时,首先在 flushContext 记录数据写入请求和回调,然后放在缓存中dataArray(实际是一个List),最后校验是否超过 batch 条数或者大小限制,超过就执行 flush ,flush 时会把 dataArray 整体序列化,然后写入 ML,写入成功之后会返回position(包含了 entry 整体的 ledgerId、EntryId 以及每个写入请求的 index)
- 有一个特例,如果一个数据自己就超过了最大大小限制,会执行两次 flush
- flush 之前 batch 的数据
- 直接把这个超长数据写入 ML
MLTransactionLogImpl 除了写入能力之外,还可以做到故障恢复,恢复主要是使用 TransactionLogReplayer 来完成的。
流程如下:
- 使用 Cursor 从
pulsar/system/__transaction_log_$TCID中读取数据,然后处理每个 Entry- Entry 反序列化为 TransactionMetadataEntry,如果是 Batch 写入的数据,则反序列化为 TransactionMetadataEntry 列表
- 然后对每一个 MetadataEntry 进行 replay 操作(如果是 Batch 数据,会跳过已经 ack 的数据)
对于每个 TransactionMetadataEntry 的处理,主要是用来恢复 MLTxnMetaStore 的 TxnMetaMap,TxmMetaMap 记录了 TC 的事务元数据信息,结构是 <Long, Pair<TxnMeta, List
>>
- Key: SequenceId,即一个事务ID
- Pair<TxnMeta, List
>:
- left 是 TxnMeta 信息,包含了TxnId(TcId + SequenceId), txn 开始时间、txn 过期时间、生产消息 partition 和消费 ack partiiton 信息(TransactionSubscription 集合,包含了 partition 和 subscription)
- right 是 Positon 列表, positon 是和一个事务有关的元数据信息在
pulsar/system/__transaction_log_$TCID的保存位置恢复的流程如下:
- NEW 操作:
- 如果 TxnMetaMap 中存在 SequenceId 记录,则 Positon 信息恢复到 TxnMetaMap 中
- 否则
- 在 TxnMetaMap 为 SequenceId 新建 TnxMeta 和 position
- 在 TransactionRecoverTracker 中记录 Open 状态的事务超时信息
- ADD_PARTITION:
- 如果 txnMetaMap 中不存在,说明事务已经终止,从 transactionLog 中删除(通过 cursor 完成 delete)
- 否则,在 TxnMeta 中更新 producerPartition 集合,并且更新 position
- ADD_SUBSCRIPTION:
- 如果 txnMetaMap 中不存在,说明事务已经终止,从 transactionLog 中删除
- 否则,在 TxnMeta 中更新 AckedPartitions 集合,并且更新 position
- UPDATE:
- 如果 txnMetaMap 中不存在,说明事务已经终止,从 transactionLog 中删除
- 否则
- 首先在 TxnMeta 中更新事务状态,然后更新 Position 信息
- 在 TransactionRecoverTracker 中更新事务状态,简单讲 Open-> committing/aborting; commiting->committed; abroting->aborted; 转换过程就是从各自的状态 map 中删除或者增加
- 如果更新状态之后的新状态是 COMMITTED 或者 ABORTED,说明事务完成,对应的元数据信息可以删除,在 cursor 中记录删除该 position 列表。
恢复流程执行完之后,在 MLTransactionMetadataStore 的 txnMetaMap 就保存了所有终止事务的信息。
恢复流程中,对于 ADD_PARTITION、ADD_SUBSCRIPTION 或者 UDPATE 操作,如果 txnMetaMap 没有 SequenceId 的记录,就直接删除,原因是事务元数据信息是按顺序写入到 txnLog 的,如果没有 Open 状态的记录,说明事务已经终止。
2.2.2.1.3 TransactionTimeoutTrackerImpl
TransactionMetadataStore 中包含一个 TransactionTimeoutTrackerImpl,其检查 ticket 时间是 100ms。当新增一个事务时,TransactionTimeoutTrackerImpl 会记录事务ID和超时时间。
记录的结构是一个优先级队列,数据结构为 <TxnTimeout, TCID, TxnID> 的 tuple3(小顶堆实现),TxnTimeout 优先级 > TCID > TxnID。
根据所有事务中超时时间最小的一个,启动一个 timeoutTask,任务会在超时时遍历队列所有元素:
- 如果事务超时,则终止这个事务
- 否则继续等待这个事务超时,超时时间为剩余的时间
到这里 MLTransactionMetadataStore 创建完毕,接下来会对其进行初始化,初始化会用到 TransactionRecoverTracker,对应的实现是 TransactionRecoverTrackerImpl。
2.2.2.1.4 TransactionRecoverTrackerImpl
TransactionRecoverTrackerImpl 在恢复事务元数据时使用,保存了 open、committing、aborting 状态的事务信息,在重放的过程中:
- 对于 NEW txn 类型的元数据:在 openTransactions map 中保存 <事务ID,timeout>
- 对于 UPDATE 类型的元数据:根据新的 state 修改其状态信息
- COMMITTING:从 openTransactions 中删除,在 committingTransactions 中添加
- ABORTING:从 openTransactions 中删除,在 abortingTransactions 中添加
- ABORTED:从 abortingTransactions 中删除
- COMMITTED:从 committingTransactions 中删除
重放完成之后
- 处理 open 事务:将 openTransactions 状态的事务添加到 TimeoutTracker 中
- 处理 committing 和 aborting 的事务:通过 transactionMetadataStoreService 来执行 endTransaction 操作,完成 commit 或者 abort 操作。
总体上的类关系如下:
TransactionMetadataStoreService
-> MLTransactionMetadataStoreProvider
-> MLTransactionMetadataStore
-> MLTransactionSequenceIdGenerator
-> MLTransactionLogImpl
-> TransactionTimeoutTracker
-> TransactionBufferClient // 终止(提交或者丢弃)事务
-> TransactionBufferHandler
2.3 事务 data flow
一个使用了事务的数据流可以被拆分为一下几个部分:
- 开始一个事务
- 在事务中生产消息
- 在事务中 ack 消息
- 结束事务
2.3.1 开始事务
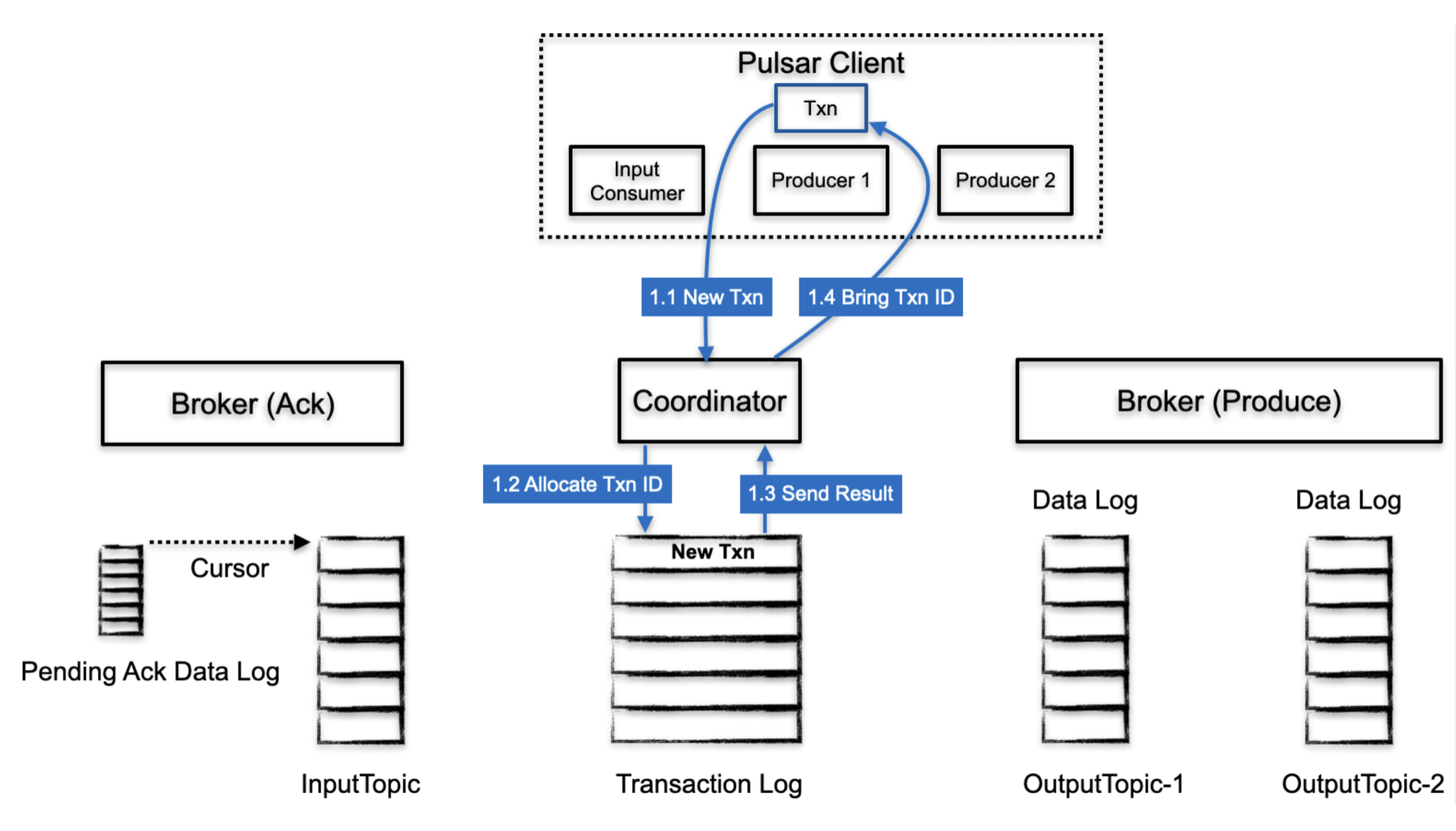
- client 首先查找 TC
- TC 分配一个 TxnID, 并且在 transaction log 中记录对应的 TnxID 和 状态(此时是 Open),保存状态可以在 TC 崩溃时恢复
- transaction log 把持久化的结果返回给 TC
- TC 把 txnId 返回给 client
2.3.1.1 客户端实现
开始事务需要先创建一个事务对象,
Transaction txn = pulsarClient.newTransaction()
.withTransactionTimeout(1, TimeUnit.MINUTES) // 设置事务超时时间,默认是 1 分钟
.build().get();
创建 txn 的过程需要选择一个 TC,选择的逻辑很简单,根据从 TransactionMetaStoreHandler 数组中轮询选择一个 TransactionMetaStoreHandler(TransactioinCoordinatorClient 中保存了每个 TC 对应的 TransactionMetaStoreHandler),然后发送一个 newTxn 的请求。
请求也会放到 TransactioinCoordinatorClient 中 timeoutQueue 中,TransactionMetaStoreHandler 在初始化时就会创建一个 timeoutTaks,用来检查 timeoutQueue 中的请求是否超时,超时的请求会返回超时异常。
2.3.1.2 Broker 实现
Broker 接收到 newTxn 请求之后,会调用 TransactionMetadataStoreService#newTransaction 处理, 找到 TCID 对应的 MLTransactionMetadataStore,然后交给MLTransactionMetadataStore#newTransaction 来处理
- 生成 TxnID: 包含两部分,TCID (mostSigBits) + TC 内部的 SequenceId(leastSigBits)
- 构建 TransactionMetadataEntry:这是写到 TxnLog(
pulsar/system/__transaction_log_$TCID, 可以看到一个 TC 上的元数据会写到同一个 ML 中) 中的事务元数据信息,此时的元数据包括:- TCID(mostSigBits)
- SequenceId(leastSigBits)
- startTime: 事务开始的时间,当前时间
- timeOut:事务超时时间
- Metadata 操作类型: TransactionMetadataOp.OPEN
- lastModifyTime: 当前时间
- maxLocalTxnId: 这个 TC 上的最大事务ID(SequenceId)
- 将 TransactionMetadataEntry 写入到 TransactionLog 中,持久化完成,返回 ML 中的持久化 position
- 为事务创建 TxnMetaImpl:包含 TxnId,open 时间,超时时间
- 在 TxnMetaMap 中记录事务信息: leastSigBits(sequenceID), <TnxMetaImpl, PositionList>
- 返回 TxnId : TCID + SequenceId
客户端接收到 TxnId之后,会将结果封装为一个 TransactionImpl,TransactionImpl 是 client 侧的事务对象,其他的事务操作都是通过 TransactionImpl 来完成,TransactionImpl 中包含:
- state:初始化完成之后,状态为 OPEN
- client: pulsarClient
- transactionTimeoutMs:事务超时时间
- txnIdLeastBits:TC 内 SequenceId
- txnIdMostBits:TC ID
- registerPartitionMap:事务中生产者涉及的分区注册表
- registerSubscriptionMap:事务中消费者涉及的分区注册表
- TransactionCoordinatorClientImpl:TC client,用来向 TC 发起事务元数据请求,一个事务使用一个 TC 保证元数据的一致性
- opFuture:
- timeout:事务超时时,将 TransactionImpl 状态置为 TIME_OUT
2.3.2 使用事务生产消息
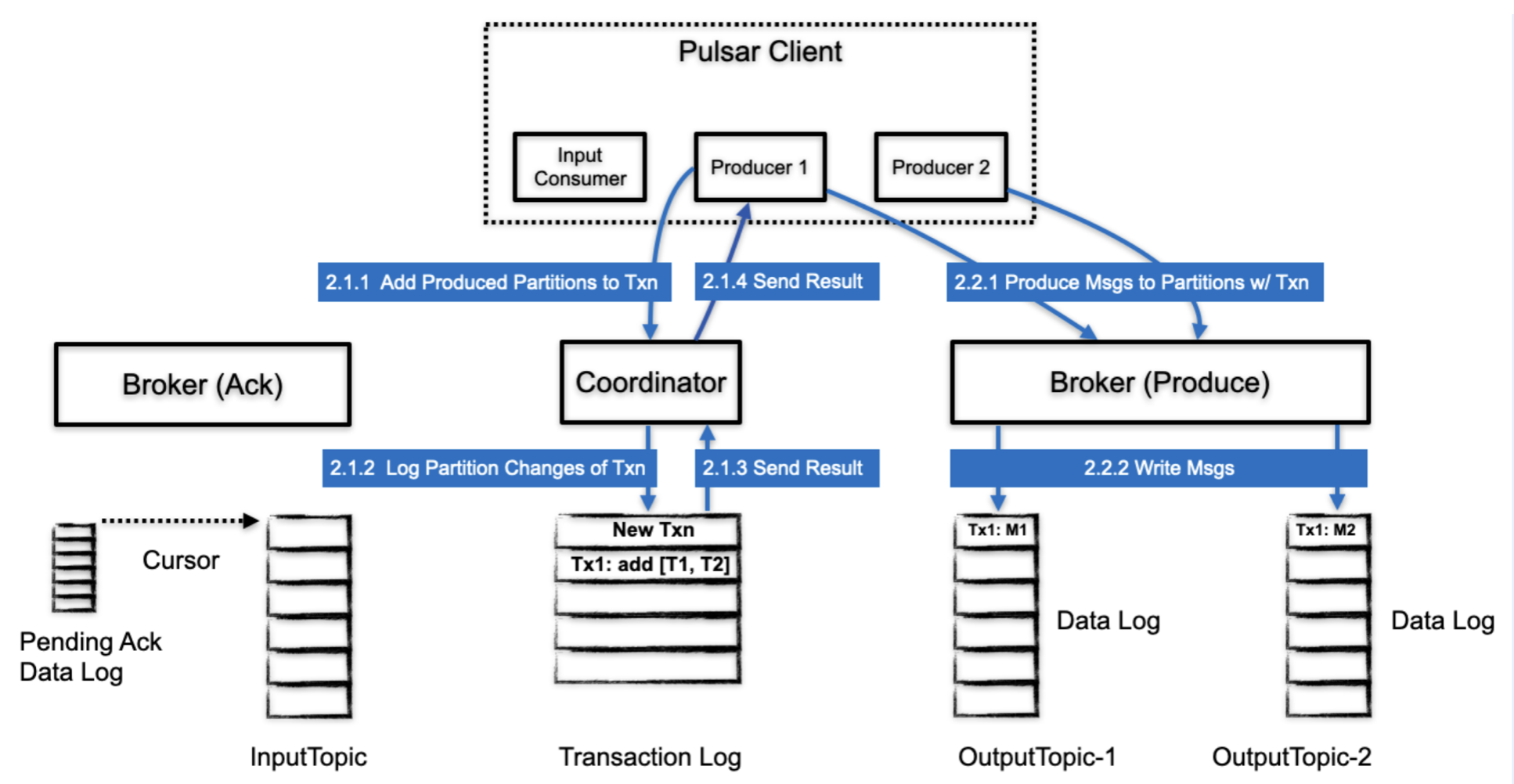
这个阶段,client 已经进入了 transaction 中,开始重复执行 consume-processs-produce 操作。这个过程中间可能会包含多条消息写入和多个ack请求。
- 在 client 生产消息之前,会把发送一个增加事务 partition 的请求到 TC
- TC 会把分区变更持久化道 transaction log 中,这个信息表明了 当前事务处理了哪些partition
- transaction log 返回持久化的结果给 TC
- TC 发送增加分区的响应给 client
- client 开始生产消息,这个流程和一般的消息生产一样,唯一的不同是消息中携带了 txnId 信息
- broker 把消息写到一个 partition
2.3.2.1 客户端实现
生产者使用事务比较简单,只需要生产消息时,添加 txn 对象即可。
producer
.newMessage(txn) // 指定事务 TransactionImpl 对象
.value("test".getBytes(StandardCharsets.UTF_8))
.send();
最终在发送之前,使用事务的 send 请求比不适用 send 的事务请求会多一个向 TC 注册分区的步骤,
return ((TransactionImpl) txn).registerProducedTopic(topic).thenCompose(ignored -> internalSendAsync(message));
先看一下 TransactionImpl#registerProducedTopic 的处理,其实就是把生产分区信息发送 TC,这个过程只会执行一次,执行之后就会在 TransactonImpl 的 registerPartitionMap 中记录。
TxnCoordinatorClientImpl#addPublishPartitionToTxnAsync -> TxnMetaStoreHandler# addPublishPartitionToTxnAsync 向 Broker 发送请求,构造出newAddPartitionToTxn 请求,包含了 TxnID 和 List
注意: TxnId 信息在消息的 metadata 中携带
2.3.2.2 服务端实现
Broker 接收到请求之后,通过
ServerCnx#handleAddPartitionToTxn
-> TransactionMetadataStoreService#addProducedPartitionToTxn
->MlTransactionMetadataStore#addProducedPartitionToTxn
来处理,首先从 txnMetaMap 中读取事务元数据信息,然后构造新的事务元数据 TransactionMetadataEntry:
- TCID + SequenceId
- MetadataOp 类型: ADD_PARTITION
- Partitions:partition 列表
- lastModifyTime: 当前时间
- maxLocalTxnId:这个 TC 上的最大事务ID(SequenceId)
然后把 TransactionMetadataEntry 写入到 MLTransactionLogImpl,写入成功之后,修改 txnMetaMap 元数据信息,在 TxnMetadata 中加入 partition 和 最新的元数据 Entry 的position。
最后给 tc-client 发送响应,表示增加分区的操作完成。
2.3.2.3 客户端实现
Producer 侧 tc-client 接收到 addPartition 的响应之后,就可以继续发送消息,发送 Txn 数据流程和正常发送数据流程一样。
发送数据会拿到一个 sendFuture,将这个 sendFuture 注册到 TransactionImp 中,这个处理是为了减少 TransactionImp 维护的 future 数量,对于同一个 TransactionImpl, 其中的 sendFuture 或者 ackFuture 有一个失败,事务都是失败的,因此可以利用这个特性,对于未完成的 send 或者 ack 共享一个 future。
2.3.2.4 服务端实现
对于事务消息,服务端是将数据直接写入到原始 topic 中的,相比于普通消息,事务消息中包含了 txn 的信息。
Pulsar 的默认事务隔离级别是 read-committed,是如何实现的?
消费数据时,最后的消费位置由 maxReadPosition 来决定,maxReadPosition 在事务提交时更新,通过这种方式保证了不会读到未提交的数据。
在消费时,是如果过滤掉 abort 类型的数据的呢?
因为在消息中,包含了事务元数据信息,所以只要保存 abort 的事务消息,就可以在消费时过滤掉 abort 的消息。这个功能通过 TopicTransactionBuffer (TB)来完成,默认实现是 TopicTransactionBuffer。每个分区上都会 有一个 TB 对象,在 PersistentTopic 初始化时创建 TB 对象,TB 会定期(完成一定数量的事务或者经过一定的时间)为 abort 的事务信息做快照(快照的作用是快速恢复 abort 的事务信息,如果没有快照,则需要遍历分区的所有数据来历史事务信息)。
TB 的初始化
- 设置 TB 状态为 None
- 设置 topic 和 timer 对象
- 设置 snapshot 的周期:number 和 time
- 初始化 maxReadPosition,初始状态为分区 LAC
- 初始化SingleSnapshotAbortedTxnProcessorImpl,主要是 snapshot 的 writer,实际上就是一个 produder,对应的 topic name是
tenent/namespace/__transaction_buffer_snapshot。开始执行 recover,
- 修改 TB 状态, None -> Initializing
- 如果没有历史 snapshot,那么就不需要回复,此时的状态更改为 NoSnapshot,恢复完成;如果有历史 snapshot ,则执行以下流程
- 从 snapshot 恢复,创建
tenent/namespace/__transaction_buffer_snapshot的 reader,snapshot 的消息都是包含 key的,key 为原始 topic 名称- 处理每一个 snapshot 消息,从中恢复出所有的 abort 事务信息到 SingleSnapshotAbortedTxnProcessorImpl,aborts <TxnId, position>,key 是 TxnId,position 是 abort marker 在原始 topic 中的位置
- 处理完 snapshot 之后,继续从原始 topoic 恢复 snapshot 之后的消息,起始位置在 snapshot 中有获取,读取所有 entry,只处理事务 entry
- 如果是事务 Marker,如果是 abort marker,在 SingleSnapshotAbortedTxnProcessorImpl aborts 中更新信息;对于 marker entry,说明事务已经结束,更新 maxReadPosition;如果 ongoing 为空,maxReadPosition 置为 LAC;如果 ongoing 不为空,maxReadPosition 置为最早的 txnID 前面位置(如果 ongoing 的事务中,txnId 小的事务消息比 txnID 大的事务消息写入的晚,会不会导致事务消息在 committed 之前被读取?)
- 如果不是事务 Marker,处理普通事务消息,如果在 ongoing 中不包含该事务,则将其添加到 ongoing 事务中,并且更新 maxReadPosition
读取完消息之后,
- 再次校验 ongoing 事务是否为空,如果为空,更新 maxReadPosition 为 LAC
- 更新状态,Initializing -> Ready
- 启动 TB 的定时 snapshot 任务
至此,TB 的初始化工作完成。
在 Broker 接收到 send 请求之后,对于事务消息,会调用 transactionBuffer.appendBufferToTxn 进行处理。首先会进行 lowWaterMark 的校验,loawarterMar 记录了 <TCID, TxnID> 的映射关系,表示一个 TC 上已经完成的事务的最低水位,小于 lowWaterMark 的事务是无效的事务。
然后将 entry 写入到 ML 中(这一步和正常数据写入一样),写入完成之后(获取了 Position),对事务消息进行处理
- 如果 ongoing 中不包含该事务,并且该事务也没有被 abort,则将其加入到 ongoing 事务中(<TxnId, Position>),即可理解为 ongoing 中保存了一个事务 ID 和该事务包含的第一条消息所在位置的映射关系
- 更新 maxReadPosition,取 ongoing 中第一个保存的事务对应的 position 的前一个位置
Ongoing 是一个 LinkedMap 类型,保持了添加顺序,因此其中的第一个 key 对应的位置就是正在进行的事务消息保存的最小 position( maxReadPosition 小于该 position),通过这种方式保证了未 commit 的消息不会暴漏给 consumer,即保证了 read-committed 隔离级别。
2.3.3 使用事务 ack 消息
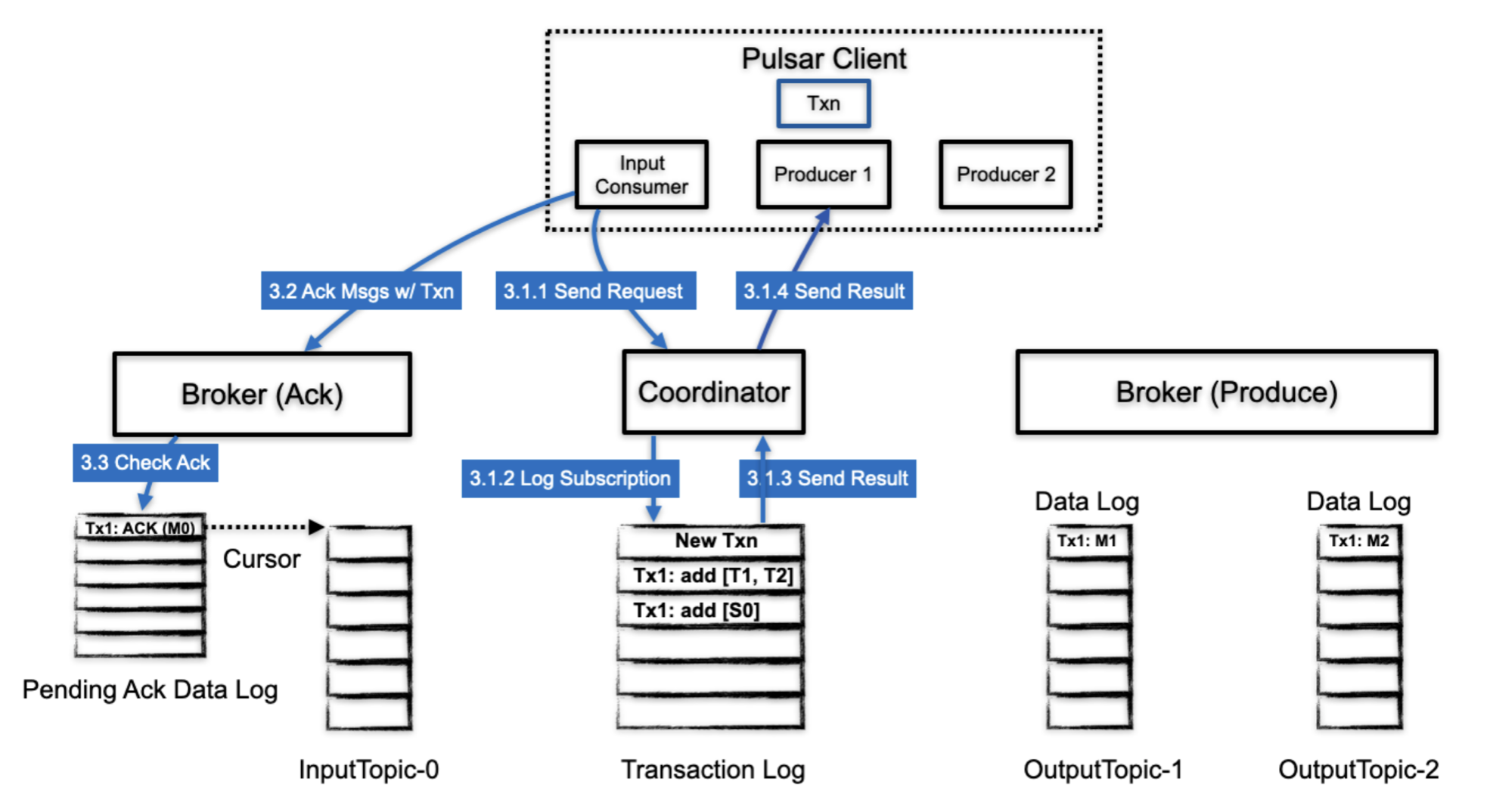
这个阶段中,会保存事务的订阅信息。
- client 向 TC 发送请求增加事务的订阅信息
- TC 把这个信息写到 transaction log
- transaction log 返回持久化结果给 TC
- tc 返回结果给 client
- client 开始 ack 消息, ack 信息中包含了 txnId信息
- broker 接收 ack 请求,会在 pending ack data log (cursor)中记录 ack信息
2.3.3.1 客户端实现
使用事务进行数据消费时,相比于正常的消费流程,主要的区别是在 ack 阶段,consumer ack 时需要指定 TransactionImpl 对象。
Consumer 初始化
Consumer<byte[]> consumer = pulsarClient.newConsumer()
.topic(normalTopic)
.subscriptionName("test")
.enableBatchIndexAcknowledgment(true) // 开启 batchIndex ack
.subscriptionType(subscriptionType)
.subscribe();
Receive 的操作和正常流程一样,区别在与 ack
for (int i = 0; i < messageCnt; i++) {
Message<byte[]> message = consumer.receive(5, TimeUnit.SECONDS);
log.info("receive msgId: {}, count : {}", message.getMessageId(), i);
consumer.acknowledgeAsync(message.getMessageId(), txn).get(); // ack 时指定 txn
}
下面来看一下 ack (individual ack)的流程,事务 ack 相比于普通的 ack 需要多执行一个 registerAckedTopic 的过程
ackFuture = txn.registerAckedTopic(getTopic(), subscription)
.thenCompose(ignored -> doAcknowledge(messageId, ackType, properties, txn));
每个 <TopicPartition, Subscription> 二元组都会注册一次,通过 TCClient.addSubscriptionToTxnAsync 向 TC 发送增加订阅的请求,请求内容包括 TxnID,topic 名称和订阅名称。
2.3.3.2 服务端实现
TC 接收到请求之后,通过 transactionMetadataStoreService.addAckedPartitionToTxn 进行处理,向 TransactionMetadataStore 中写入 Txn、topicPartition 和 subscription 的关系。
构建新的 TransactionMetadataEntry:
- TCID, transactionID
- TransactionMetadataOp.ADD_SUBSCRIPTION
- topicPartition 和 subscription
- modifyTime、maxLocalTxnId
然后将这次的元数据变更写入到 TransactionLog,写入完成之后得到 Position 信息,更新 TxnMetadata 信息
- 加入 txnSbuscription (topicPartition 和 subscription)信息
- 加入新的 position 信息
元数据更新完成,向 consumer 返回响应。
2.3.3.3 客户端实现
Consumer 接收到 register 成功的响应之后,开始执行 ack,这里有一个和普通 ack 的区别,事务 ack 不会使用 AcknowledgmentsGroupingTracker。
假设是一个 BatchMessage 的 individual ack,会构建一个 bitSet,然后向 broker 发送 ack 请求到 Broker。
2.3.3.4 服务端实现
Broker 接收到事务 ack 请求之后
- 计算 ack 消息的数量,然后更新 unack 消息数
- 如果是 share 类型的消费,并且不是 batchMessage,从 consumer 的 pendingAck 中删除 position
接下来开始执行事务 ack,事务 ack 的主要目的是在缓存 ack 请求,不直接作用到订阅的 cursor上,直到事务终止(commit、abort、timeout)时才实际作用到 cursor,这个能力是通过 PendingAckHandle 来实现的。
PendingAckHandle 针对于一个订阅,每个持久化订阅都有一个 PendingAckHandle。
PendingAckHandle 在创建订阅时初始化,实现是
PendingAckHandleImpl,先看下初始化的过程
- 将状态置为 None
- 初始化 topicName、subscriptionName、persistentSubscription
- 初始化 PendingAckHandle 状态信息
- 初始化 TransactionPendingAckStoreProvider, 默认实现是 MLPendingAckStoreProvider, 用来提供 PendingAckStore,PendingAckStore 的主要作用是保存 ongoing 状态事务的 ack 信息。
TransactionPendingAckStoreProvider 会首先检查是否已经初始化过,检查逻辑是判断是否存在 pendingAckStore 对应的 managedLedger(名称为
persistent://tenant/namespace/topic-$subName__transaction_pending_ack), 如果没有初始化过,则跳过,延迟初始化(可能使用不上,所以推迟初始化动作)。如果已经存在,则执行初始化逻辑,初始时首先进行执行的是 TransactionPendingAckStoreProvider 状态变化:None -> Initializing,接下来主要是创建 pendingAckStore,并且对 pendingAckStore 进行 replay。先看下 PendingAckStore 的创建过程(在这之前会变更状态,None -> Initializing)
拼接 pendingAckStore 的 topicName:
persistent://tenant/namespace/topic-$subName__transaction_pending_ack获取 ManagedLedger config:如果 pendingAckStore 的 topic 已经存在,则获取对应的配置,否则获取原始 topic 的 ML 配置
open pendingAckStore 对应的 ML
为 pendingAckStore ML 创建 cursor,cursorName 是
__pending_ack_state, initializePosiiton 为 earlieset创建 MLPendingAckStore:
- MLPendingAckStore 包含了 ML,Cursor,以及原始订阅的 cursor;
- 一个 bufferedWriter 用来持久化 ack 信息;
- 一个 pendingAckLogIndex, pendingAckLogIndex 是一个 skipListMap,用来协助删除无用的数据(下文有详细解释)。
然后开始执行 PendingAckStore 的 replay 恢复操作,恢复过程就是不断读取 PendingAckStore ML 中的数据,然后从这些数据中恢复出历史状态的过程,起始位置是 PendingAckStore cursor 的 markDelete 位置,读取直到 LAC。
读取到的数据反序列化之后是 PendingAckMetadataEntry,然后开始恢复流程:
- currentIndexLag + 1
- 如果不是 abort 或者 commit 消息,从 PendingAckMetadataEntry 解析出 ack 请求中的 position 信息,更新 maxAckPosition
- 如果 currentIndexLag > maxIndexLag,在 pendingAckLogIndex 保存 maxAckPosition 和 logPosition(pengdingAckStore ML) 的映射关系,并且更新 currentIndexLag = 0
- 根据 pendingAckMetadata 的类型做不同处理(暂时只考虑 individual ack):
- ABORT:首先判断 individualAckOfTransaction 是否存在,如果不存在,说明还没有 individual ack(individual ack 前会确保创建 individualAckOfTransaction),没有 pending ack 信息的 abort 可以忽略;否则从 individualAckOfTransaction 获取 txn 对应的 pendingAck 状态信息,执行 abort 操作,abort 事务的操作逻辑比较简单:
- 如果是 batch 消息,并且 individualAckPositions 中包含该 position,则需要恢复 abort 的 ackset 对 individualAckPositions 影响
- 其他情况,直接从 individualAckPositions 删除 position
- 最后从 individualAckOfTransaction 删除 txn 对应的内容
- COMMIT:首先判断 individualAckOfTransaction 是否存在,如果不存在,说明还没有 individual ack(individual ack 前会确保创建 individualAckOfTransaction),没有 pending ack 信息的 commit 可以忽略;否则从 individualAckOfTransaction 获取 txn 对应的 pendingAck 状态信息,执行 commit 操作,commmit 就是把 individualAckOfTransaction 对应事务的 pendingAck 信息调用原始订阅进行 acknowledge,然后从 individualAckOfTransaction 删除 txn 对应的内容
- ACK:如果是 ack 请求,则从 pendingAckMetadata 中解析出所有需要 ack 的 <PositionImpl, BatcherSize>, 然后通过
pendingAckHandle.handleIndividualAckRecover来处理,将这些已经持久化的 pendingAck 信息,恢复到 pendingAckHandle 的内存结构中 individualAckOfTransaction 和 individualAckPositions- 读取完所有的 entry 之后,执行恢复完成处理逻辑
- pengdingAckHandle 状态 Initializing -> Ready
- 处理 pending 的 ack 请求
事务的 ACK 是通过 PendingAckHandle 来执行的,PendingAckHandle 调用 PendingAckStore 来先保存 ack 信息,保存的内容被封装为 PendingAckMetadataEntry,包含:
- PendingAckOp:PendingAckOp.ACK
- ackType: individual or cumulative
- pendingAckMetadataList: 包含了每个 ack 的 position (LedgerId、EntryId、AckSet)信息 以及 batchSize 信息的列表
- TxnID: TCID+SequenceID
然后将 PendingAckMetadataEntry 写入到 PendingAckStore 的 ML 中,写入完成之后,得到 ackMetadata 在 PendingAckStore 的 position 信息
- currentIndexLag 自增:currentIndexLag 表示 pendingAckStore 中保存的,还没有在 pendingAckLogIndex 中记录的 ack 请求数
- 如果 currentIndexLag 超过了 maxIndexLag(默认是 500),在内存中(pendingAckLogIndex)记录 maxAckPosition 和 pendingAckStore 中 log position 的映射关系, maxAckPosition 是 ack 请求中最大的 ack 位置。然后将 currentIndexLag 设置为 0
即在 pendingAckLogIndex 中记录了实际 ack 请求中的最大 position 和 在 pendingAckStore ML 中 position 的对应关系
假设一个 pendingAckStore 的 ML 对应的 currentLedger ID 为 1001,有一系列 ack 请求:
- <1,1>
- <1,3>
- <1,2>
- <2,1>
- <2,3>
- <2,2>
对应时刻的 pendingAckLogIndex 为 :
maxAckPosition logPositoiin
<1,1> <1001, 0>
<1,3> <1001, 1>
<1,3> <1001, 2>
<2,1> <1001, 3>
<2,3> <1001, 4>
<2,3> <1001, 5>
假设订阅此时的 markDelete 位置为 <1,3> ,那么<1,3> 对应的 logPosition <1001,2>之前的数据都可以被删除。
- 在执行完 ackMetadata 在 pendingAckStore 中的保存之后,执行 pengdingAckStore 数据的清理逻辑
- 遍历
pendingAckLogIndex,查找小于订阅 markDelete 的最大 key(maxAckPosition)作为 deletePosition - 对 pendingAckStore 的 cursor 执行 markDelete 操作,位置就是 deletePosition
- 遍历
思考:这种数据清理的逻辑依赖于事务 ack 的不断执行,如果没有更多事务 ack 请求,会不会导致遗留 pendingAckStore 的 ledger 清理不掉呢?
到这里,事务的 ack 请求已经被持久化到了 pendingAckStore 中,然后会遍历 ack 请求的所有 position 信息做一些校验:
- 校验 position 是否小于 markDeletePosition,如果是,说明 ack 的是已经删除的 position,抛出异常
- 如果是 batchMessage 的 ack:
- 校验当前 position 的 bitSet 和 订阅中的相同 positioin 的 ackSet 是否重复,如果重复,抛出异常
- 校验 individualAckPositions 中是否存在该 positioin,如果存在,继续校验 和 individualAckPositions 中的 ackSet 是否重复,如果重复,抛出异常
- 如果不是 batchMessage 的ack:校验 individualAckPositions 中是否存在该 positioin,如果存在说明 ack 重复,抛出异常
校验完成之后,将本次 ack 信息保存在内存结构中,供后续校验使用,遍历 ack 请求中的所有 position,首先保证以下两个数据结构的初始化:
// 记录了每个事务的 ack 信息,对于 value.key 是 <LedgerId, EntryId>,对于 batchMessage,value.value 包含了 ackSet
// ack 是会对 ackSet 做合并;对于非 batchMessage,value.value 和 value.key 内容一致
LinkedMap<TxnID, HashMap<PositionImpl, PositionImpl>> individualAckOfTransaction;
// 记录了历史 ack 信息,key 是 <LedgerId, EntryId>, value 部分是 ack 请求中的内容,left 是 position 信息,right 是
// batchSize
ConcurrentSkipListMap<PositionImpl, MutablePair<PositionImpl, Integer>> individualAckPositions;
然后,如果 position 不是 batch position,将 position 信息添加到 individualAckOfTransaction 和 individualAckPositions 中;
如果 position 是 batch position,
- 将 position 信息添加到 individualAckOfTransaction 中,如果 position 已经存在,则ackSet 会合并,不存在则直接添加;
- 将 positioin 信息添加到 individualAckPositions 中,如果存在,则合并 ackset,更新 batchSize;如果不存在则直接添加;
到这里,broker 处理事务 ack 的逻辑基本完成。
最后,如果如果是 share(Key_share)类型的消费,并且是 batch 消息,检查 pendingAckHandle中 batch 消息是否全部 ack,如果全部 ack,从 consumer 的 pendingAcks 中删除。
到这里,broker 对于事务的 ack 处理结束。
2.3.4 事务结束
最后事务会被提交或者丢弃。
2.3.4.1 结束事务 request
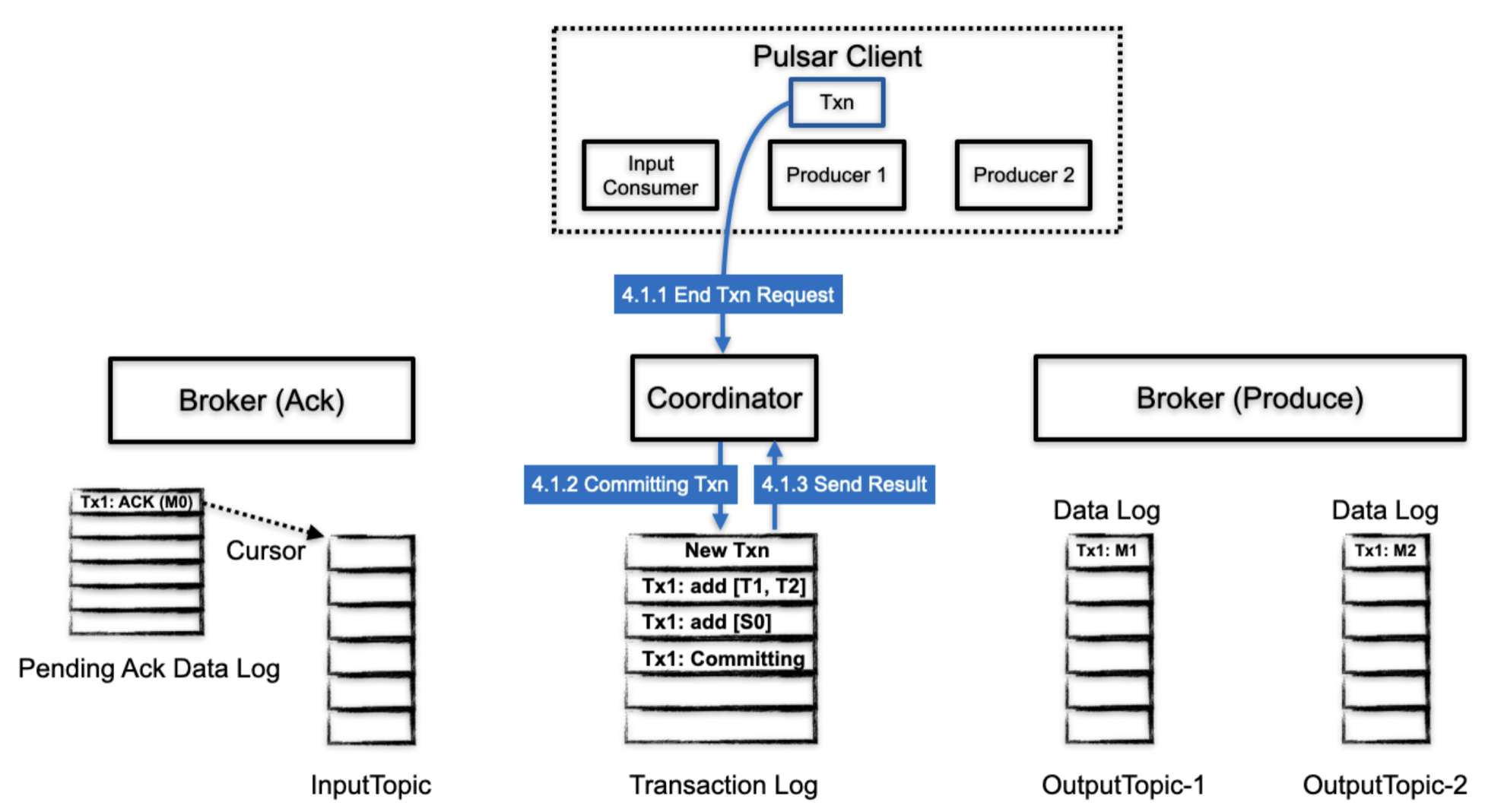
client 处理完一个事务之后,会发起一个 结束事务的请求
- client 发送结束事务的请求给 TC,请求中包含了提交或者丢弃的标识
- TC 向 transaction log 中写入 COMMITTING 或者 ABORTING 信息
- transaction log 返回持久化结果
2.3.4.2 事务提交-- 阶段 1
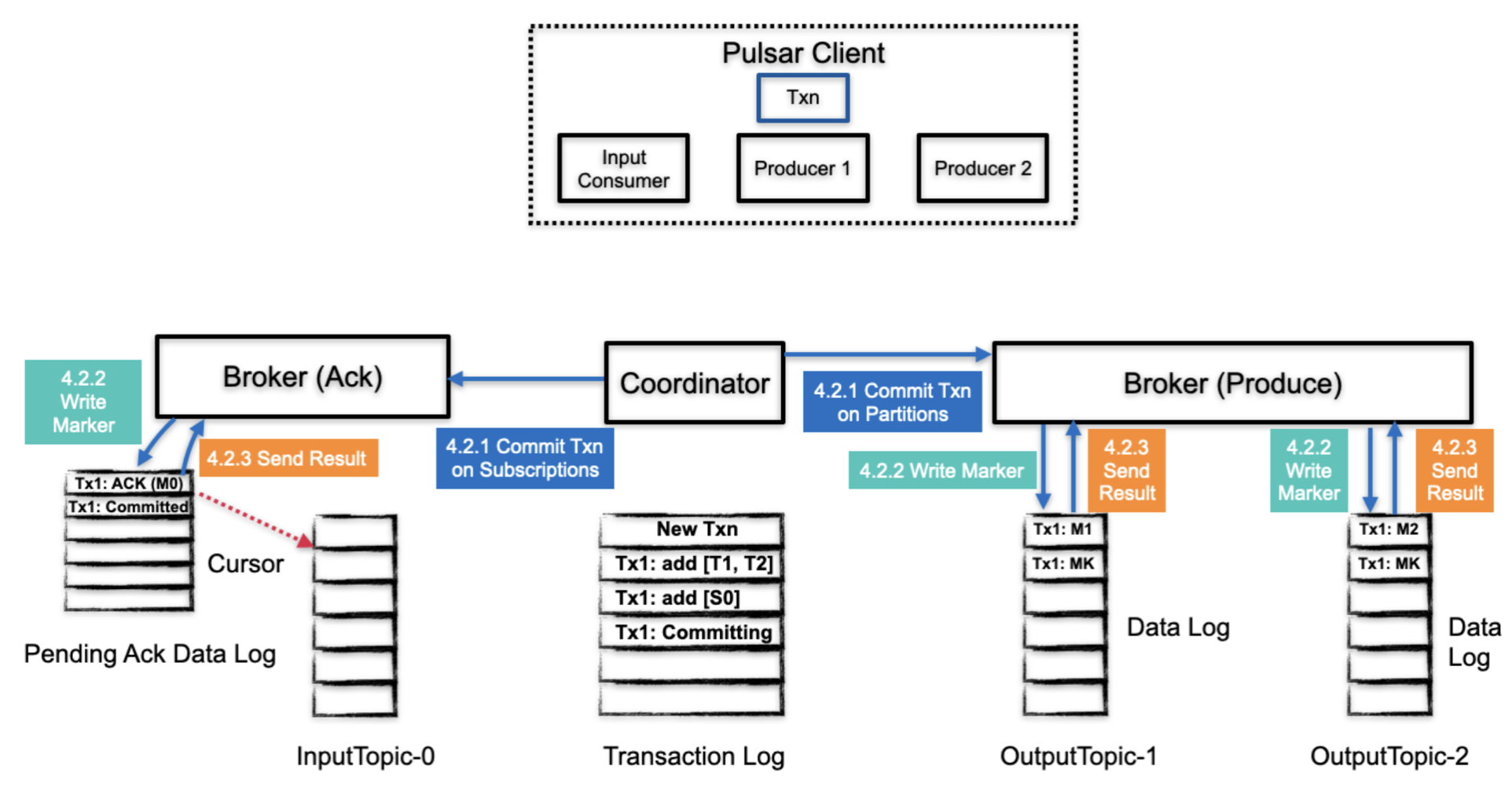
TC 开始处理提交或者丢弃请求,这个过程会涉及到事务中所有消息(所有分区)
- TC 同时在订阅(消费 ack)和分区(生产)上提交事务
- 对于分区来讲,是在实际的消息中写入一个事务的marker消息,表示事务的提交或者丢弃;
- 对于 pending ack log 来讲,会在 pending ack data log 中写入一个事务(提交或者丢弃)的信息
- 分区 和 pending ack 返回结果给 broker,cursor 移动到下一个位置
2.3.4.3 事务提交--阶段2
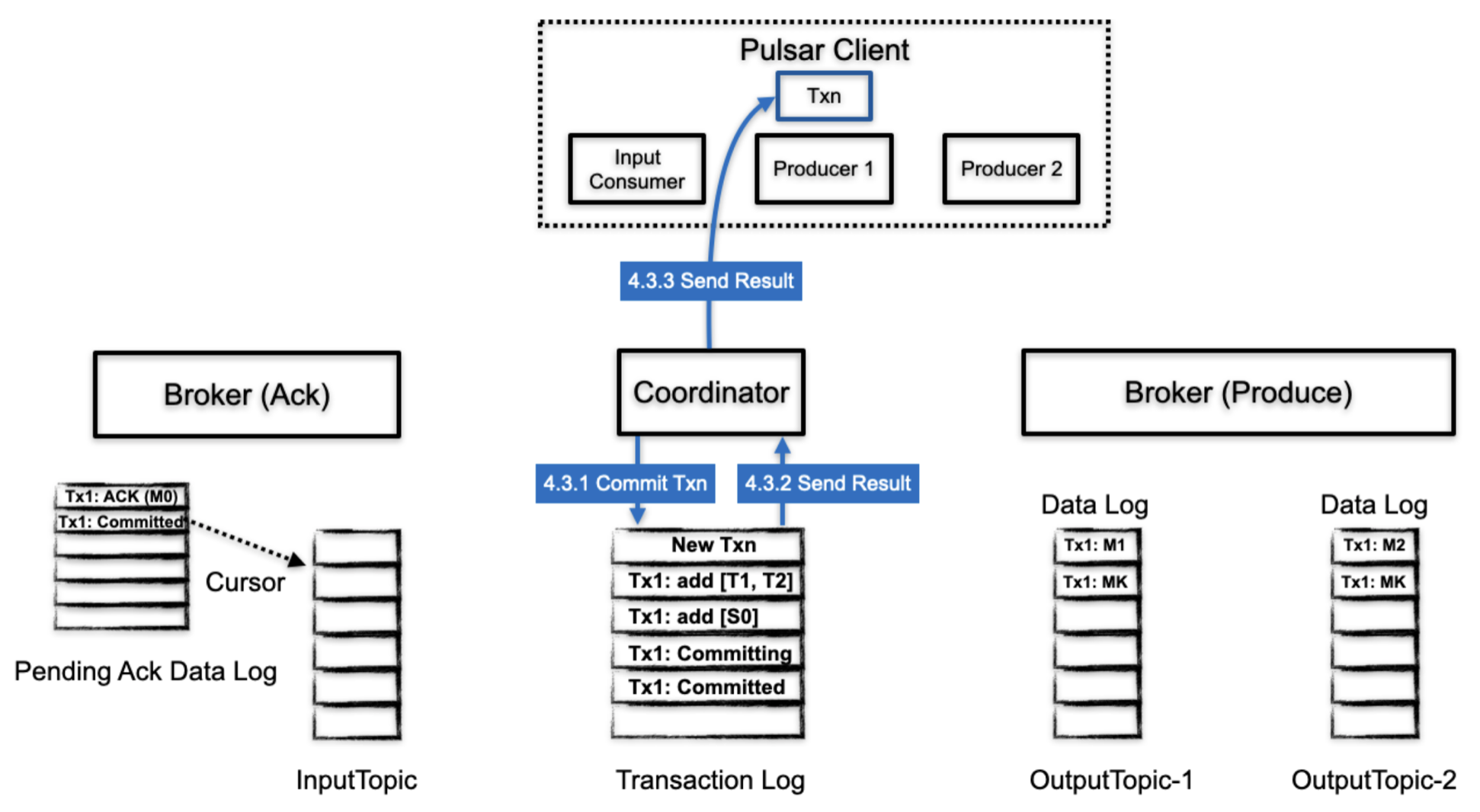
- 当事务中所有的生产消息和ack信息都已经被 commit 或者 abort,TC 会将最终状态写入到 transaction log,transaction log 中这个事务相关的信息也可以被安全的删除。
- transaction log 返回结果给 TC
- TC 返回结果给 client
2.3.4.4 客户端实现
客户端 commit 或者 abort 事务的方式如下:
transaction.commit().get(); // 提交
transaction.abort().get(); // 丢弃
对应的就是通过 tcClient 向 broker 发送 endTransaction 的请求(实际是 TransactionMetaStoreHandler.endTxnAsync)
handler.endTxnAsync(txnID, TxnAction.COMMIT);
handler.endTxnAsync(txnID, TxnAction.ABORT);
Coomit 和 Abort 都是通过同样的请求 newEndTxn 来终止事务的,内部包含了不同的 TxnAction 类型。
2.3.4.5 服务端实现
Broker 接收到 endTxn 的请求之后的处理流程总体如下:
- 修改 Txn 的状态,包括增加一个 transaction log 和 内存状态修改,此时的状态为 COMMITTING 或者 ABORTING
- 通过 TransactionBuffer(注意不是事务生产中对应的 TB) 来终止事务
- 修改 Txn 的状态为 COMMITTED 或者 ABORTED,并且从内存 txnMetaMap 中删除该 TxnID 对应的信息,并且从 transactionLog 中删除该事务的所有 position(完成的事务不需要保存其信息)
整个过程需要在 TC 更新两次状态,首先是 COMMITTING/ABORTING,然后是 COMMITTED/ABORTED。
我们重点来看第二步,即 TransactionBuffer 终止事务的流程,这个终止流程分为两个步骤:
- 消费事务相关的 pendingAck 的处理
- 生产事务相关的事务消息的处理
在事务终止的处理中,会涉及到 lowWaterMark 的概念,那么 lowWaterMark 是什么呢,有什么作用?
lowWaterMark 指在一个 TC 内部,当前未完成状态的事务之前的一个事务 ID,即 tnxMetaMap 中记录的 firstKey - 1.
lowWaterMark 可以被 TB 和 PendingAckHanlde 用来作为删除无用事务的参考,lowWaterMark 之前的 txn 都可以被安全的删除。
消费事务的终止
终止事务包括 COMMIT 和 ABORT 两种操作类型,携带的参数有 topic、subscriptioin、TxnID 和 lowWatherMark。
case TxnAction.COMMIT_VALUE:
return tbClient.commitTxnOnSubscription(tbSub.getTopic(), tbSub.getSubscription(), txnID.getMostSigBits(),
txnID.getLeastSigBits(), lowWaterMark);
case TxnAction.ABORT_VALUE:
return tbClient.abortTxnOnSubscription(tbSub.getTopic(), tbSub.getSubscription(), txnID.getMostSigBits(),
txnID.getLeastSigBits(), lowWaterMark);
tbClient 和对应 topic 分区链接,发送请求到相应的 Broker,Broker 接收到终止订阅的之后,会根据不同的 end 类型执行不同的操作:
PersistentSubscriptioin#endTxn
-> PendingAckHandle.commitTxn
-> PendingAckHandle.abortTxn
ComimitTxn
首先,会在 pendingAckStore 中增加一个 CommitMarker 的记录,PendingAckMetadataEntry (类型是 COMMIT)
然后,从 individualAckOfTransaction 中取出 PendingAck 信息,调用原始订阅 ackNowledge 方法,将 pendingAck 信息实际作用到原始订阅中,并且从 individualAckOfTransaction 中删除 txnID 对应的信息
最后,更新 pendingAckHandle 中的 lowWaterMark 映射关系(如果 end 请求中的 lowWatherMark 更大,就按照 end 请求内容更新);然后根据最新的 lowWatherMark 处理 individualAckOfTransaction,如果 individualAckOfTransaction 第一个事务的 leastSigBit 小于等于最新的 lowWaterMark,说明事务可以删除,执行 abort 操作
AbortTxn
首先,会在 pendingAckStore 中增加一个 AbortMarker 的记录,PendingAckMetadataEntry (类型是 ABORT)
然后,从 individualAckOfTransaction 中取出 PendingAck 信息,遍历所有信息,从 individualAckPositions 删除掉 abort 的消息的影响,包含 batch position 以及 非 batch positoin,并且从 individualAckOfTransaction 中删除 txnID 对应的信息
非 Batch message 的处理比较简单,从 individualAckPositions 中删除对应的 position 即可
Batch Message 的处理相对复杂,需要处理 bitSet 来恢复到事务之前的状态。
在执行 individualAck 时,如果 ack 的 position 是一个 batch positoin,假设 batchSize = 4, ledgerId = 1, EntryId = 1,第一次 ack batchIndex = 0 的位置,即 ackRequeset-1 对应的 bitSet 为 T T T F (T 表示 true, F 表示 false,ack 请求中 F 表示 ack)。
由于是首次 ack,直接添加到 individualAckPositions(individualAckOfTransaction 的处理类似) 里,individualAckPositions 的内容为:
key value
<1,1> <<1,1, (TTTF)>, 4>
第二次 ack batchIndex = 1 的位置,ackRequeset-2 对应的 bitSet 为 T T F T,第二次添加时,individualAckPositions 中已经存在对应位点的 ack 信息,因此需要将 ackSet 进行合并,即将两个 bitSet 执行 AND 操作
T T T F
AND
T T F T
RES: T T F F
individualAckPositions 的内容为:
key value
<1,1> <<1,1, (TTFF)>, 4>
假设 ackReqeuset-1 和 ackRequeset -2 属于 tnx1, ackRequeset-3 属于 txn2。
第三次 ack batchIndex = 2 的位置,ackRequeset-3 对应的 bitSet 为 T F T T,第三次添加时,individualAckPositions 中已经存在对应位点的 ack 信息,因此需要将 ackSet 进行合并,即将两个 bitSet 执行 AND 操作
T T F F
AND
T F F T
RES: T F F F
individualAckPositions 的内容为:
key value
<1,1> <<1,1, (TFFF)>, 4>
Tnx2 执行 abort 操作,首先从 individualAckOfTransaction 获取 txn2 对应的 pendingAck 信息,这里就是 ackRequest-3 的内容,<<1,1>, <1,1, TFTT>>, 这个信息在 individualAckPositions 中也存在。
根据 ackRequeset-3 的 ackSet 构建 Bitset(thisBitSet),即 T F T T
- 从 individualAckPositions 获取 positon 对应的 batchSize, 4
- 对 bitSet (T F T T)从 0~4 执行 flip 操作,结果为(thisBitSet) F T F F
- 从 individualAckPositions 中获取 <1,1> 获取 position 的总体 bitset(otherBitSet),即 T F F F
- otherBitSet.or(thisBitSet), 即 T F F F or F T F F ,otherBitSet 的结果为 T T F F,对应于 ack-Requeset2 作用之后的结果
- 如果 otherBitSet 的所有位置都是 T,说明没有 ack 信息,则从 individualAckPositions 中删除这个位置对应的信息;否则将 otherBitSet 结果更新到 individualAckPositions
接下来,由于事务已经 abort,unack 的数据需要重新推送,broker 重新把数据推送给 consumer
最后,更新 pendingAckHandle 中的 lowWaterMark 映射关系(如果 end 请求中的 lowWatherMark 更大,就按照 end 请求内容更新);然后根据最新的 lowWatherMark 处理 individualAckOfTransaction,如果 individualAckOfTransaction 第一个事务的 leastSigBit 小于等于最新的 lowWaterMark,说明事务可以删除,执行 abort 操作
生产事务的终止
生产事务的终止也包含 COMMIT 和 ABORT 操作
if (TxnAction.COMMIT_VALUE == txnAction) {
return transactionBuffer.commitTxn(txnID, lowWaterMark);
} else if (TxnAction.ABORT_VALUE == txnAction) {
return transactionBuffer.abortTxn(txnID, lowWaterMark);
}
COMMIT
TB 提交事务首先会构建一个 CommitMarker,然后把这个 Marker Entry 写入到原始 Topic 里,写入成功之后
- 从 ongoing 中删除该事务,然后更新 MaxReadPositoin(最早 ongoing 事务 entry 的前一个位置)
- 更新 TB 本地 lowWaterMark 映射关系,然后检查 ongoing 事务中小于 lowWaterMark 的事务,对这些事务执行 abort 操作
ABORT
TB 丢弃事务会先构建一个 AbortMarker,然后把这个 Marker Entry 写入到原始 Topic 里,写入成功之后
- 从 ongoing 中删除该事务,然后更新 MaxReadPositoin(最早 ongoing 事务 entry 的前一个位置),
- 在 snapshotAbortedTxnProcessor 中记录 abort 的会务消息(用来在消费时过滤消息), 放置的内容是 <TxnId , maxReadPosition>
- 清理 aborts 列表,遍历 abort 状态的事务,如果对应的 position ledger 已经不存在,那么这个事务可以被删除
- 检查是否需要执行 TB snapshot
- 更新 TB 本地 lowWaterMark 映射关系,然后检查 ongoing 事务中小于 lowWaterMark 的事务,对这些事务执行 abort 操作