
在 MQ 实际的使用中,消费数据时,可能会遇到消息处理异常或者需要推迟处理的场景,这里就涉及到消息的重推逻辑。
Pulsar 自己提供了一些消息重推的能力。本文主要介绍 pulsar 的消息重推机制。
消息获取(拉取/推送)机制
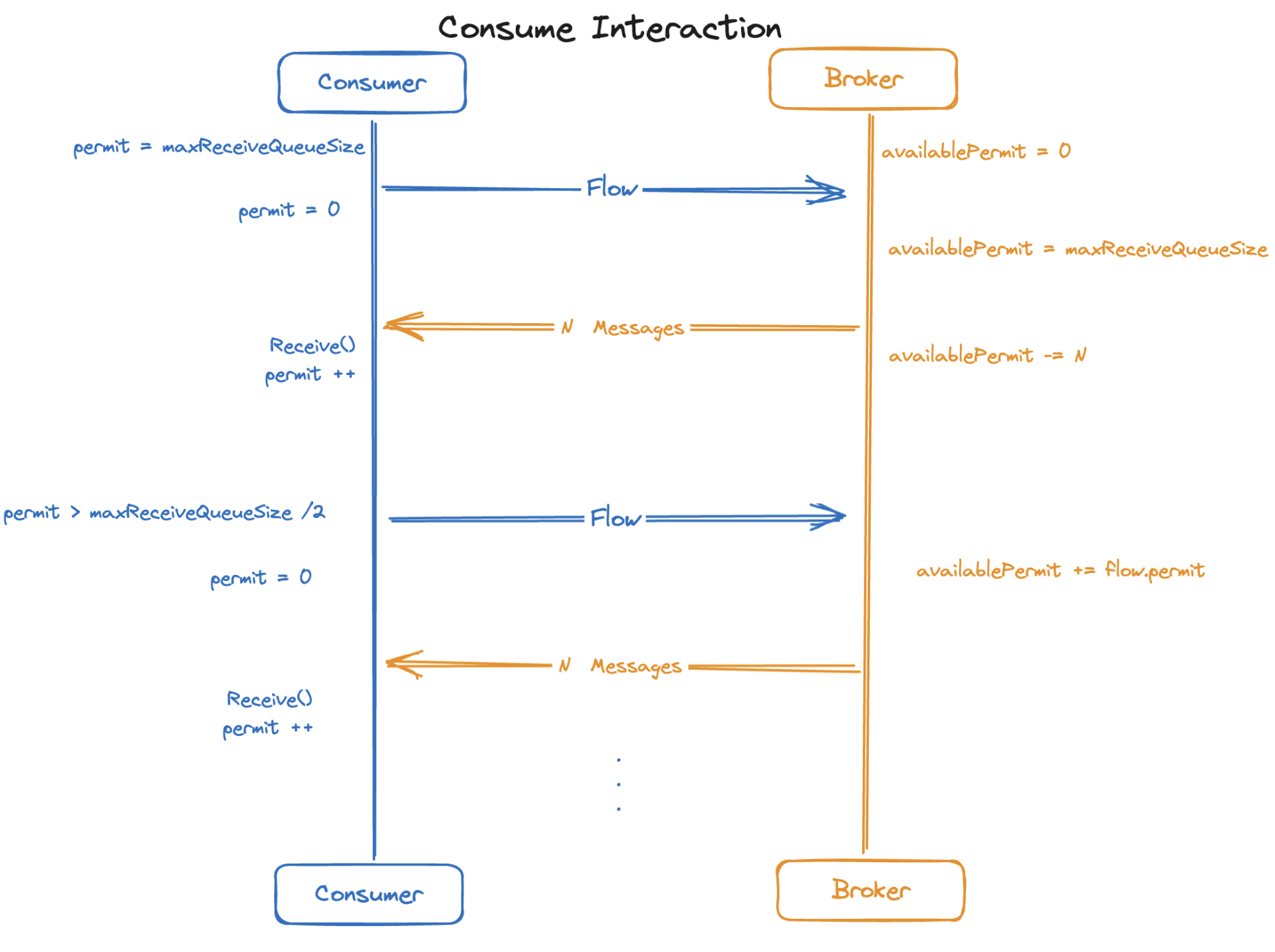
Pulsar 的消费采用了推、拉结合的消息获取机制,Consumer 获取消息之前会首先通知 Broker(FLOW 请求),Broker 会根据配置的 ReceiveQueue 大小以及 Consumer 当前可以接收的消息数量来推送消息给 Consumer。
详细的交互流程如下图所示:
-
Consumer 在创建之后,会以 MaxReceiveQueue 的大小作为 Permit 值,这个值就是 Consumer 可以缓存的的最大消息条数。
-
然后,Consumer 向 Broker 发起 FLOW 请求,携带 permit 信息(Consumer permit 减少到 0),Broker 接收之后会记录这个 Permit 作为 Consumer 的 AvailablePermit,AvailablePermit 决定 Broker 可以向 Consumer 发送数据的数量(实际是在读取数据时判断);
-
如果 AvailablePermit > 0, Broker 开始读取数据(假设有 N 条),然后推送给 Consumer,推送之后,AvailablePermit 自减 N;
-
Consumer 接收到消息之后,并不会直接返回给用户,而是放在 receiveQueue 中,当用户调用 receive() 方法来获取消息时,Consumer 将 permit + 1;
-
当 Permit > MaxReceiveQueueSize / 2,Consumer 会再次发起 Flow 请求,并且携带当前的 Permit 值。
上述流程,就是 Consumer 和 Broker 的消息传递过程。
在默认的情况下,数据推送给 Consumer 之后,就完全交给用户处理,数据不会重复推送。
这种方式满足不了需要重推的场景,下面会介绍目前 Pulsar 的几种重推机制。
SDK 统一的重推
一个比较直观的做法是超过一定时间不 ack 就重新推送,目前 Pulsar 提供了通过超时时间来控制数据重推的能力,consumer 可以配置 ackTimeout(默认关闭),在设置了 ackTimeout 之后,client 会构建一个 unAckedMessageTracker,用户 receive() 的所有的消息都会被 unAckedMessageTracker 跟踪。
用户 ack 消息时,会从 unAckedMessageTracker 删除,对于没有 ack 的消息,unAckedMessageTracker 会有定时任务来检查,如果已经超过了 ackTimeout 时间,则会触发重推。
重推是通过 redeliverUnackMessage 来实现的,也就是说 unAckedMessageTracker 会主动发起 redeliver 的请求,broker 会根据请求的 MessageId 信息重新推送。
AckTimeout 可以在 consumer 初始化时设置。
Consumer<String> consumer = pulsarClient.newConsumer(Schema.STRING)
.ackTimeout(10, TimeUnit.SECOND)
用户决策的重推 -- NegativeAck
通过 AckTimeout 实现的重推,是 SDK 内部统一实现的,用户不能控制重推的行为,如果用户希望根据自己的使用场景,决定哪些消息需要重推,Pulsar 提供了 NegativeAck 的能力。
NegativeAck 和 ackTimeout 方式类似,也有一个 NegativeAcksTracker,NegativeAcksTracker 只会跟踪用户主动调用 negativeAcknowledge 方法的 messageId,重推的逻辑也是通过 redeliverUnackMessage 实现。
NegativeAck 可以设置 Redelivery 的 delay 时间
Consumer<String> consumer = pulsarClient.newConsumer(Schema.STRING)
.negativeAckRedeliveryDelay(1001, TimeUnit.MILLISECONDS)
使用的时候,需要明确调用
// call the API to send negative acknowledgment
consumer.negativeAcknowledge(message);
用户决策的重推 -- RLQ
除了 NegativeAck 的方式,用户还可以通过重试队列( RLQ )来实现主动的消息重推,RLQ 一般会使用在用户暂时不能处理某些消息,并且希望之后再处理的场景。
Pulsar 提供了 reconsumeLater() 方法来实现重试队列,和 Negative 不同的是,RLQ 会创建一个新的 topic,topic 的格式是
TopicName-SubscriptionName_RLQ, 每次 reconsumeLater() 时,都会产生一个新的消息写入到 RLQ topic 中,并且会对之前的消息 ack。
设置了 RLQ 的 consumer,SDK 内部默认会启动 RLQ 的订阅,所以 RLQ 的消息也会被 consumer 消费到。
RLQ 是通过 deadLetterPolicy 来配置的(DLQ 下文会解释),
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic("my-topic")
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.enableRetry(true)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(maxRedeliveryCount)
.build())
.subscribe();
RLQ topic 中的消息属性中会添加一下信息:
| Special property | Description |
|---|---|
REAL_TOPIC | 原始 topic 名称 |
ORIGIN_MESSAGE_ID | 原始 MessageId |
RECONSUMETIMES | 重复消费的次数 |
DELAY_TIME | 投递的延迟时间 |
RLQ 也需要主动调用:
consumer.reconsumeLater(msg, 3, TimeUnit.SECONDS);
为重推次数加上限制--DLQ
对于数据持续处理失败,一直重试并不是一个很好的策略,此时死信队列(DLQ)就是一个比较好的选择,DLQ 允许用户将持续处理失败的数据写入到一个独立的 Dead Letter Topic 中,DLQ 的数据需要单独的订阅来消费。
DLQ topic 的格式为 TopicName-SubscriptionName_DLQ。DLQ 需要为重试设置一个上限,当重试次数超过上限之后,就会被写入到 DLQ topic 中。
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic("my-topic")
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(maxRedeliveryCount)
.build())
.subscribe();
如果配置了 DLQ,那么使用 ackTimeout、negativeAck 或者 RLQ 引起的数据重推都会触发 DLQ,也就是说重试的次数达到上限之后,都会被写入到 DLQ topic 里。
重试次数的统计有所区别:
- ackTimeout 和 negativeAck 都是通过 Redelivery 机制来计数的,SDK 发起 Redelivery 请求之后,broker 侧的 RedeliveryTracker 会记录重推的次数,并且在推送给 Consumer 的 Message 中会包含 RedeliveryCount 的字段
- 对于 RLQ,则是从 RECONSUMETIMES 属性中获取重复消费的次数,这个属性在 Client 生成,并且也是在 client 计数
问题
If you are going to use negative acknowledgment on a message, make sure it is negatively acknowledged before the acknowledgment timeout.
按照官网的说法,使用 negativeAck 时,需要在 ackTimeout 之前执行 negativeAck。
在配置了 ackTimeout 或者 DLQ (配置 DLQ policy,如果没有配置 ackTimeout,会增加一个默认的 ackTimout = 30s 的配置)时,negative 需要在 ackTimeout 生效前调用。
应为 negative 是用户的手动调用,所以优先级更高。
在单个分区的消费中,即 ConsumerImpl 中,这个行为是可以得到保证的,即 negativeAck 的逻辑优先执行
public void negativeAcknowledge(MessageId messageId) {
negativeAcksTracker.add(messageId);
// Ensure the message is not redelivered for ack-timeout, since we did receive an "ack"
unAckedMessageTracker.remove(messageId);
}
可以看到,调用 negative 时,会从 unAckedMessageTracker 中删除。
但是在多分区 topic 或者 多 topic 的订阅中,即 MultiTopicsConsumerImpl 中,这个行为并没有得到保证,
public void negativeAcknowledge(MessageId messageId) {
checkArgument(messageId instanceof TopicMessageIdImpl);
TopicMessageIdImpl topicMessageId = (TopicMessageIdImpl) messageId;
ConsumerImpl<T> consumer = consumers.get(topicMessageId.getTopicPartitionName());
consumer.negativeAcknowledge(topicMessageId.getInnerMessageId());
}
可以看到,MultiTopicsConsumerImpl#negativeAcknowledge 时,是查找了具体的 ConsumerImpl 对象,然后通过 ConsumerImpl 对象来完成的 negativeAcknowledge,这里看起来是没问题的,但是 MultiTopicsConsumerImpl 在 receive 时,将 message 放入到了自己的 unAckedMessageTracker 中进行跟踪,所以 MultiTopicsConsumerImpl 在调用 negativeAck 时,message 会被同时放在 MultiTopicsConsumerImpl 的 unAckedMessageTracker 以及 ConsumerImpl 的 negativeAcksTracker 里,这里会触发两次重推,并且不能保证 negative 的逻辑先执行。
测试验证:
-
启动一个 MultiTopicsConsumerImpl/启动一个单分区并且设置了DLQ的订阅
-
设置 ackTimeout 时间小于 negativeAckRedeliveryDelay;
-
调用 negativeAck
-
观察哪个逻辑先触发
https://github.com/apache/pulsar/pull/20750 已经修复该问题
几种重推和 DLQ 的关系
如果配置了 DLQ,那么使用 ackTimeout、negativeAck 或者 reconsumeLater 引起的数据重推都会触发 DLQ,也就是说重试的次数达到上限之后,都会被写入到 DLQ topic 里。
重试次数的统计有所区别:
ackTimeout和negativeAck都是通过 Redelivery 机制来计数的,SDK 发起 Redelivery 请求之后,broker 侧的RedeliveryTracker会记录重推的次数,并且在推送给 Consumer 的 Message 中会包含 RedeliveryCount 的字段- 对于 RLQ,则是从
RECONSUMETIMES属性中获取重复消费的次数,这个属性在 Client 生成,并且也是在 client 计数
总的来说,Apache Pulsar 提供了多种消息重推的方式,用户可以结合自己的场景,灵活使用,满足自己的业务需求。