
Pulsar broker负载均衡原理和实现
[toc]
Pulsar 的负载均衡策略的目的是为了将负载均匀的分配在集群不同的 broker 上。
1. Broker 分类
从负载均衡的角度看,broker 可以分为两类
- leader broker:负载汇总、更新负载信息
- 其他 broker:计算自己的负载信息并且上报
1.1 Ledger 选举
Ledger Broker 是通过选举产生的,broker 启动时会启动一个 LeaderElectionService,LeaderElectionService 负责 ledger 的选举、监听 ledger 变化等。
LeaderElectionService 会创建一个 LeaderElectionImpl,LeaderElectionImpl 来执行具体的选举、监听等工作。
选举过程需要依赖 zk,选举的对应的 znode 是 /loadbalance/leader,这个节点是临时节点,可以在 leader 掉线时触发其他 broker 的 wathcer 重新选举 leader。
- 如果这个节点的内容已经存在,如果是其他节点,说明已经 leader 已经存在
- 如果不存在,说明还没有 leader,尝试成为 leader,将自己的信息写入到选举 znode 下(版本号 -1)
- 如果遇到 BadVersion Exception,说明 leader 已经有其他 broker 成为 leader,将自己置为 Following 状态
- 如果写入成功则成为 leader,修改状态为 Leading
1.2 Ledger 的任务
在 Broker 当选为 Leader 之后,会启动两个任务
- LoadSheddingTask:负载根据配置的 bundle shedding 策略,将负载高的 bundle 卸载,周期任务,配置为
loadBalancerSheddingIntervalMinutes,默认是 1 分钟 - LoadResourceQuotaUpdaterTask:汇总所有的负载信息,并且写入到 zk上,周期任务,配置为
loadBalancerResourceQuotaUpdateIntervalMinutes,默认是 15分钟
2. 负载均衡的组成
负载均衡主要涉及到几个部分:
- 计算每个节点负载 :需要每个节点的参与,每个 broker 都会定期的将负载信息上报到 zookeeper
- 负载汇总:leader 负载从读取每个 broker 的上报负载信息,然后汇总写入到 zk
- bundle shedding:leader 对于负载高的节点计算需要卸载的 bundle
- bundle placement:leader 为未分配的 bundle 选择一个 broker 来放置
- bundle split: 切分负载高的 bundle
2.1 节点负载计算
每个 Broker 在启动时,都会启动负载管理服务:
-
启动
ModularLoadManagerImpl -
启动
LoadReportUpdaterTask: 每个 broker 节点负载的计算和上报,就是通过LoadReportUpdaterTask来实现的,周期任务,配置为loadBalancerReportUpdateMinIntervalMillis, 默认是 5s。
broker 的负载信息时使用
LocalBrokerData来保存的,包含了整个 broker 的负载以及相关配置信息:
配置信息:
- serviceUrl : pulsarServicerUrl 和 webServiceUrl 信息
- protocol handle 信息:protocols
- advertisedListeners
- broker 版本信息:brokerVersionString
- LoadManager 类名:loadManagerClassName
- 支持的 topic 类型: persistent 和 non-persistent topic 是否支持
物理资源使用利率:cpu、memroy、directMemeory、bandwithIn、bandwithOut;ResourceUsage 类型(包含使用率和上限)
实时负载信息:
- msgRateIn、msgRateOut、msgThroughputIn、msgThroughputOut
- numTopics、numBundles、numConsumers、numProducers
- 当前 broker 分配的 bundles、上次更新到现在新分配的 bundle、上次更新到现在丢失的 bundle
开始时间:startTimestamp
最后更新时间:lastUpdate
2.1.1 负载管理器的初始化
LoadManager 的初始化是通过反射完成的,LoadManager 的类型 在conf 中配置,默认是 ModularLoadManagerImpl,有一点比较特别的地方需要注意:ModularLoadManagerImpl 并且不是一个LoadManager的子类, ModularLoadManagerImpl 继承自 ModularLoadManager, 通过 ModularLoadManagerWrapper封装成 一个ModularLoadManagerImpl, ModularLoadManagerWrapper 实现了LoadManager接口。
// 如果是LoadManager,创建之后直接初始化
if (loadManagerInstance instanceof LoadManager) {
final LoadManager casted = (LoadManager) loadManagerInstance;
casted.initialize(pulsar);
return casted;
// 如果是 ModularLoadManager,则封装成 ModularLoadManagerWrapper,然后初始化
} else if (loadManagerInstance instanceof ModularLoadManager) {
final LoadManager casted = new ModularLoadManagerWrapper((ModularLoadManager) loadManagerInstance);
casted.initialize(pulsar);
return casted;
}
下文以默认的配置 ModularLoadManagerWrapper 来讲述。
ModularLoadManagerImpl 在初始化(initialize)时:
- 创建 LocalBrokerData、BundleData、ResourceQuota、TimeAverageBrokerData 的 cache
- 创建 zk 的监听器,监控 broker 节点变化和 sesseion expiration
- 创建具体的 brokerHostUsageImpl,默认是 LinuxBrokerHostUsageImpl,LinuxBrokerHostUsageImpl 会定时计算机器负载信息,默认时间为 1分钟,包括以下信息:
- CPU 负载:计算从上次统计到当前时间的平均值(需要支持 cGroup)
- 内存负载:计算从上次统计到当前时间的平均值
- bandwithIn 和 bandwithOut:计算从上次统计到当前时间的平均值
- 创建 BundleSplitterTask:用来支持 bundle split
- 创建 SimpleResourceAllocationPolicies:支持 IsolationPolicies
- 创建 LoadSheddingStrategy:用来只是 bundle shedding
ModularLoadManagerImpl 初始化之后 start,流程如下:
首先,会初始化负载均衡的基本信息 lastData 和 localData,每次更新前会对比 lastData 和 localData, 判断是否更新到 zk
- lastData:LocalBrokerData类型,最后一次更新前的数据,包括
- serviceUrl 信息
- protocol 信息
- 是否支持 persistentTopic、non-persistentTopic
- localData:LocalBrokerData类型,表示 broker 的负载信息,包括:
- serviceUrl 信息
- protocol 信息
- broker 版本信息
- 是否支持 persistentTopic、non-persistentTopic
- loadmanager 类名
然后,初始化两个 zk 路径:
- broker 负载路径:
/loadbalance/brokers/$lookupServiceAddress - broker 平均负载路径:
/loadbalance/broker-time-average/$lookupServiceAddress
接下来,更新 LocalBrokerData:
- 获取系统资源使用率
- cpu、memroy、directMemeory、bandwithIn、bandwithOut:这个过程会覆盖 LinuxBrokerHostUsageImpl 计算的内存使用(按照 JVM 的配置来计算使用率)
- 获取 bundle stats(保存在 lastStats 中):bundle stats 信息从 pulsarStats 中获取,pulsarStats 是由 broker 周期更新的,配置项为
statsUpdateInitialDelayInSecs,默认为 1分钟- 更新 topic 数量
- 遍历 bundle 下 所有 topic
- 累加 producer 数量、consumer 数量
- 累加 msgRateIn、msgRateOut、msgThroughputIn、msgThroughputOut
- 更新 LocalBrokerData 的 资源使用 和 bundle 信息
- 更新 bundles,同时记录新增的 bundle 和 丢失的 bundle
- 更新 bundle 数量、topics 数量、producer 数量、consumer 数量
- 更新 msgRateIn、msgRateout、throughputIn、throughputOut
接下来,将初始的负载信息更新到 zk
-
将 LocalBrokerData 信息更新到
/loadbalance/brokers/$lookupServiceAddress路径下 -
在
/loadbalance/broker-time-average/$lookupServiceAddress路径下更新一份初始的 timeaverage 负载信息
最后会执行 updateAll 操作:
- 清理掉线 broker,和历史 active 的 broker 对比,计算出掉线的 broker 信息,如果是 leader
- 删除
/loadbalance/broker-time-average/$lookupServiceAddress信息 - 回调 LoadSheddingStrategy 的 onActiveBrokersChange
- 回调 placementStrategy 的 onActiveBrokersChange
- 删除
- 更新本地的全量 broker 负载信息(本地全量信息为 LoadData,包括 brokerData、bundleData 和 recentlyUnloadBundle 信息)
- 更新
/loadbalance/brokers/$lookupServiceAddress路径下最新的负载信息 - 删除掉掉线 broker 的负载信息
- 更新
- 更新本地全量的 bundle 信息 bundleData ,上一个步骤已经获取了 broker 最新的负载信息,从 broker 负载中可以获取 broker 上最新的 bundle 信息
- 遍历 broker,获取每个 broker 最新的 bundle 负载信息
- 处理每个 bundle
- 如果在 bundleData 中存在该 bundle,则使用最新的负载信息更新
- 如果不存在,尝试从 bundleCache 中获取
- 如果 cache 命中直接返回,然后使用最新的负载信息更新;
- 如果 cache miss,则从
/loadbalance/resource-quota/namespace/teantn/ns/0x12000000_0x14000000读取 resourceQuota 配置,然后使用 quota 中配置作为初始 BundleData(shrotTerm 和 longTerm 均达到最大采样次数),然后用最新的负载信息更新
- 从 bundleData 中删除已经不使用的 bundle 信息,如果是 leader,从
/loadbalance/bundle-data/teantn/ns/0x12000000_0x14000000删除 bundle 的 负载信息 - 处理 preallocate
TimeAverageMessageData 包含了 msgRateIn/Out,throughputIn/Out 等数据,是一个抽样的结果,可以配置抽样次数
- 没有达到抽样次数之前,历史结果和新结果的占比是变化的,历史结果占比为(采样次数-1)/ 采样次数,新结果占比为 1/采样次数
- 达到抽样次数之后,结果依旧会更新,但是历史结果和新结果的占比不再变化、
Pulsar 有 shrotTerm 和 longTerm 两种指标,默认最大采样次数分别为 10 和 1000
举例:以 msgRate 为例,msgRate 采样结果为 1,2,3,4,5,最大采样次数为 3
- 第一次采样,采样次数为1,msgRate = 1,历史 msgRate 为 0, 结果为 ,((1-1)* 0+ 1)/1 = 1
- 第二次采样,采样次数为2,msgRate = 2,历史 msgRate 为 1, 结果为 ,((2-1)* 1 + 2)/ 2 = 3/2
- 第三次采样,采样次数为3,msgRate = 3,历史 msgRate 为3/2, 结果为 ,((3-1)* 3/2 + 3)/ 3 = 2
- 采样次数达到 3 之后,不在增加
- 第四次采样,采样次数为4,msgRate = 4,历史 msgRate 为2, 结果为 ,((3-1)* 2 + 4)/ 3 = 8/3=2.67
- 第五次采样,采样次数为5,msgRate = 5,历史 msgRate 为 8/3, 结果为 ,((3-1)* 8/3 + 5)/ 3 = 31/9 = 3.4
2.1.2 负载上报任务
负载上报由 LoadReportUpdaterTask 来完成,周期执行,默认周期为 5s,配置为 loadBalancerReportUpdateMinIntervalMillis。
负载上报的第一步是计算负载信息 LocalBrokerData。
- 获取系统资源使用率
- cpu、memroy、directMemeory、bandwithIn、bandwithOut:这个过程会覆盖 LinuxBrokerHostUsageImpl 计算的内存使用(按照 JVM 的配置来计算使用率)
- 获取 bundle stats(保存在 lastStats 中):bundle stats 信息从
pulsarStats中获取,pulsarStats是由 broker 周期更新的,配置项为statsUpdateInitialDelayInSecs,默认为 1分钟- 更新 topic 数量
- 遍历 bundle 下 所有 topic
- 累加 producer 数量、consumer 数量
- 累加 msgRateIn、msgRateOut、msgThroughputIn、msgThroughputOut
- 更新 LocalBrokerData 的 资源使用 和 bundle 信息
- 更新 bundles,同时记录新增的 bundle 和 丢失的 bundle
- 更新 bundle 数量、topics 数量、producer 数量、consumer 数量
- 更新 msgRateIn、msgRateout、throughputIn、throughputOut
接下来,判断是否将负载信息更新到 zk,判断有几个条件
- 最大上报时间:
loadBalancerReportUpdateMaxIntervalMinutes, 默认是 15 分钟,超过则执行上报 - 负载变化百分比:
loadBalancerReportUpdateThresholdPercentage, 默认是 10 %, 超过则上报,注意这的负载变化取得是各类负载变化的最大值- 系统资源使用率变化
- msgRateIn +msgRateOut 变化
- throughputIn +throughputOut 变化
- bundle 数变化
上述条件满足一个都会更新到 zk,则将负载信息更新到 zk /loadbalance/brokers/$lookupServiceAddress 路径下。
更新到 zk 之后,将自上次上报新增和删除的 bundle 信息清理,并且更新 lastdata 为 localData。
2.2 负载汇总
负载汇总的任务是主要是 leader 来完成的,ledger 在选举完成之后,会启动一个定时任务 LoadResourceQuotaUpdaterTask 来执行这个操作,配置为 loadBalancerResourceQuotaUpdateIntervalMinutes,默认是 15分钟。
Leader 使用 LoadData 来表示整个负载情况,包含 broker 信息、bundle 信息、和最近 unload 的 bundle 信息。
/**
* Map from broker names to their available data.
*/
private final Map<String, BrokerData> brokerData;
/**
* Map from bundle names to their time-sensitive aggregated data.
*/
private final Map<String, BundleData> bundleData;
/**
* Map from recently unloaded bundles to the timestamp of when they were last loaded.
*/
private final Map<String, Long> recentlyUnloadedBundles;
LoadResourceQuotaUpdaterTask 任务
- 会将所有 broker 上报到 zk 的 bundle 信息汇总,并且写入到 zk 的
/loadbalance/bundle-data/tenant/namespce/$bundle节点 - 汇总所有 broker 的负载信息,将 timeAverageData 写入到 zk 的
/loadbalance/broker-time-average/$Broker节点
这两个信息都是从 loadData 中读取得到的。
那么 loadData 中的数据是什么时候更新的呢?
LoadManager 初始化时注册了一个 listener,会监听 zk 数据的变动,当 /loadbalance/brokers 下数据内容发送变化时,会触发回调逻辑,更新所有 broker 的信息,也就是说每当 broker 负载信息超过阈值上报时,都会触发这个回调的处理(所有 broker 节点都会执行)。
public void handleDataNotification(Notification t) {
if (t.getPath().startsWith(LoadManager.LOADBALANCE_BROKERS_ROOT)) {
brokersData.listLocks(LoadManager.LOADBALANCE_BROKERS_ROOT)
.thenAccept(brokers -> {
reapDeadBrokerPreallocations(brokers);
});
try {
executors.execute(ModularLoadManagerImpl.this::updateAll);
} catch (RejectedExecutionException e) {
// Executor is shutting down
}
}
}
可以看到其实回调还包括对于 broker 节点变更的处理。
2.2.1 broker 节点变更处理
这里的处理主要是针对 preallocatedBundleToBroker。
比对 loadData 中的 Broker 信息和当前存活的 broker 信息,如果节点已经不存活,从 preallocatedBundleToBroker 中删除相关 broker 的信息。
preallocatedBundleToBroker 中的信息是 <bundle, broker> 格式的映射
2.2.2 updateAll
最后会执行 updateAll 操作,udpate all 包含了多种类型的处理,会对本地的 loadData 做更新,最后检查是否需要执行 bundle split。
首先,是对于掉线 broker 的处理,和历史 active 的 broker 对比,计算出掉线的 broker 信息,如果是 leader
- 删除
/loadbalance/broker-time-average/$lookupServiceAddress信息: - 回调 LoadSheddingStrategy 的 onActiveBrokersChange
- 回调 placementStrategy 的 onActiveBrokersChange
然后,更新 loadData 中 broker 负载信息:
- 从
/loadbalance/brokers/$lookupServiceAddress路径下读取 broker 最新的负载信息,更新到 loadData 中 - 从 loadData 中删除掉线 broker 的负载信息
接下来, broker 最新的负载信息已经更新,包含了 bundle 信息(lastStat),使用从 broker 负载中可以获取的 bundle 信息 来更新更新 loadData 的 bundle 信息,bundle 信息主要是两个内容,shortTerm 和 longTerm 负载,在处理每个 bundle 时:
- 如果 loadData 中已经包含了 bundle 信息,则使用最新的数据来更新负载(TimeAverageMessageData 的 update)
- 如果不包含则尝试从 zk 获取 bundleData,路径为
/loadbalance/bundle-data/tenant/namespace/$bundle,- 如果 zk 上有 bundle 负载信息,获取并使用最新的数据来更新负载
- 如果没有,则构建一个默认的 bundleData,并使用最新的数据来更新负载
创建一个默认的 BundleData,shortTerm 和 longTerm 的采样上限为 10 和 1000,在更新 bundle 的 shortTerm 和 longTerm 时数据来源有两种方式
- 从 ResourceQuota 获取,ResourceQuota 内容在 zk 路径
/loadbalance/resource-quota/namespace/bundle下,使用 resourceQuota 来更新 BundleData- 否则,直接使用默认的 stats 来更新,默认的 msgRateIn/Out 是 50,msgThroughputIn/Out 是 50000,都是一个很小的值
-
如果 bundle 不活跃(比如 bundle 卸载之后没加载),并且当前是 leader 节点,则从
/loadbalance/bundle-data/teantn/ns/0x12000000_0x14000000删除 bundle 的 负载信息 -
处理预分配的 bundle,把已经分配的 bundle 从 预分配的中删除
预分配是在给 bundle 分配 broker 时,为 bundle 选择一个 broker 之后:
- 从 loadData 下获取 broker 的信息 BrokerData,将分配信息加入到 BrokerData 的 preallocatedBundleData map 中
- 将分配信息保存在 LoadManager 的 preallocatedBundleToBroker map 中
-
处理 loadData 中 brokerData 的 timeAverageData 负载信息,计算过程是,根据 broker 上报的 bundle 信息来更新 timeAverageData,最后更新到 brokerData 中。
-
更新 brokerToNamespaceToBundleRange <broker,<namespaceName,Set
>>,使用各节点的 bundle 信息和预分配的 bundle 来更新这个 map
最后,执行 bundleSplit ,bundleSplit 有几个必要的前提:
- split 开关打开: 配置项是
loadBalancerAutoBundleSplitEnabled - 必须是 leader 节点
- broker 节点数大于 1
如果条件都满足,则根据 split 的条件来检查需要执行bundle split 操作 bundle,
# namespace 的最大 bundle 数,默认是 128,超过这个上限时,不会继续 split bundle
loadBalancerNamespaceMaximumBundles
# bundle 最大 topic 数量,超过这个限制,可以执行 split
loadBalancerNamespaceBundleMaxTopics=1000
# bundle 最大 session 数量(producer + consumer),默认是 1000,超过可以执行 split
loadBalancerNamespaceBundleMaxSessions
# bundle 的最大 msgRate(in+out),默认是 30000,超过可以执行 split
loadBalancerNamespaceBundleMaxMsgRate=30000
# bundle 的最大 msgThroughput,默认是 100MB,超过可以执行 split
loadBalancerNamespaceBundleMaxBandwidthMbytes=100
loadData 中的 brokerData 和 bundleData 信息已经更新,遍历所有 broker 的 lastStats 的所有 bundle
- 跳过 topic 数量小于 2 的 bundle
- 对于每个 bundle,从 bundleData 中取出 longTermData,获取 longTermdata 的 msgRate 和 msgThroughtput
- 满足以下条件之一可以执行 split
- Topic 数量 > loadBalancerNamespaceBundleMaxTopics
- loadBalancerNamespaceBundleMaxSessions > 0, 并且 bundle 的 producer + consumer 数量 > loadBalancerNamespaceBundleMaxSessions
- msgRate > loadBalancerNamespaceBundleMaxMsgRate
- msgThroughtput > loadBalancerNamespaceBundleMaxBandwidthMbytes
执行 split 之前要判断 bundle 数量是否超过 loadBalancerNamespaceMaximumBundles,超过不会继续 split,不超过才会执行 split 操作,因为这个过程中会检查多个 bundle 是否需要执行 split,因此在完成检查之前,会记录需要 split 的 bundle 信息,来避免多个 bundle 的 split 导致最终的 bundle 数量超过 loadBalancerNamespaceMaximumBundles。
至此,就拿到了需要执行 split 的 bundles 信息,下面来看如何执行 split 操作,对于一个需要 split 的 bundle:
- 首先判断 bundle 上下限是否满足切分条件,upperBound > lowerBound + 1
- 从 loadData 的 bundleData 中移除 bundle 信息,避免 bundle 再次被选中
- 从当前 broker 的 localData 中移除 bundle 信息
- 从 bundleCache 中,让 bundle 缓存失效,以便 split 之后加载最新的 bundle 信息到缓存中
- 从 zk 路径
/loadbalance/bundle-data/teantn/ns/$bundle下删除 bundle 数据 - 判断切分之后的 bundle 是否需要 unload
- 配置项为
loadBalancerAutoUnloadSplitBundlesEnabled - 另外也会受到 isolation 以及 namesapce 亲密性配置影响
- 配置项为
- 调用 admin 命令执行 bundle 的 split 操作
Broker 接收到 bundle split 请求之后的处理逻辑如下:
- 权限校验
- 检验 split 算法,支持的算法包括四种:"range_equally_divide", "topic_count_equally_divide", "specified_positions_divide", "flow_or_qps_equally_divide"
- 检验 namespace 的 ownerShip,会重定向到目标集群
- 校验是否只读,只读则不允许操作
- 校验 namespace bundle 的 ownership
- 开始执行 bundle split,切分的行为和具体的 split 算法相关,切分之后,可能是多个也可能是两个 bundle,切分算法会计算出 split 的 boundaries 信息,根据新的 boundaries 就可以计算出新的 bundle 信息
到这里,updateAll 的操作完成,可以看到当 zk 上 broker 负载有变化时,每个 broker 都会感知到变化,并且更新本地的全局负载信息。如果是 leader 节点,还会执行 bundle split 的操作。
2.3 bundle shedding
bundle 的 shedding 和 bundle split 时的 unload 还有些不一样,bundle split 的 unload 只会发生在 bundle split 之后,bundle 的 shedding 是有负载均衡任务周期性执行的。
bunde shedding 在发生在 leader 上,基本原理就是:
- leader 汇总所有 broker 的负载信息
- 选出 overload 的 broker
- 选出要 shedding 的 bundle
- 执行bundle 的 unload
在 leaderElection 完成之后,成为 leader 的 broker 会启动一个 LoadSheddingTask 任务,LoadSheddingTask 会首先判断是否开启了 loadShedding 功能,需要同时开启负载均衡和负载 shedding:
- loadBalancerEnabled:负载均衡的开关,总开关
- loadBalancerSheddingEnabled:负载 shedding 的开关
在开启负载 shedding 的前提下,首先,判断 broker 数量,如果数量 <= 1,不执行 shedding;
然后 清理 loadData 中的 recentlyUnloadedBundles,过滤 unload 时间超过 loadBalancerSheddingGracePeriodMinutes 的 bundle,并且重 recentlyUnloadedBundles 中删除
loadBalancerSheddingGracePeriodMinutes表示在一段时间内,一个 bundle 不会被 shed 多次,避免频繁 unload,recentlyUnloadedBundles 中记录了最近 unload 的bundle 信息
接下来, 查找需要 unload 的 bundle,查找 unload bundle 的方法有多种,目前有四种算法:
- OverloadShedder
- ThresholdShedder
- UniformLoadShedder
- DeviationShedder
我们分别来看其工作原理。
2.3.1 OverloadShedder
Overload shedder 是一种基于最大系统资源使用率的 shedding 算法,核心配置是
# OverloadShedder 算法判定 broker overload 的阈值
loadBalancerBrokerOverloadedThresholdPercentage=85
资源利用率的计算从 broker 上报的负载信息中取所有物理资源(CPU/Direct Memory/bandwidthIn/bandwidthOut)的最大值
public double getMaxResourceUsage() {
// does not consider memory because it is noisy by gc.
return max(cpu.percentUsage(), directMemory.percentUsage(), bandwidthIn.percentUsage(),
bandwidthOut.percentUsage()) / 100;
}
注意这里为了避免 GC 的影响,没有考虑 heap memory 的影响。
如果使用率超过了 loadBalancerBrokerOverloadedThresholdPercentage,则判定此 broker 是 overload 的 broker,需要从这个 broker 上 shedding 负载。
这时候需要计算需要卸载多少负载,OverloadShedder 只支持 msgThroughtput 维度计算
- 卸载的比例 percentOfTrafficToOffload:currentUsage - loadBalancerBrokerOverloadedThresholdPercentage + 0.05,注意这里加了 0.05 额外卸载的部分,可以避免卸载之后 broker 的使用率依旧很接近 loadBalancerBrokerOverloadedThresholdPercentage,从而避免频繁卸载
- 卸载的数据量 minimumThroughputToOffload:broker 的 (throughputIn + throughputOut) * percentOfTrafficToOffload:currentUsage
- 选择卸载的 bundle,遍历 broker 的所有 bundle 信息,按照 shortTermData 的 (throughputIn + throughputOut)排序(逆序),从 throughput 从大到小选择 bundle(会过滤掉最近 unload 的 bundle),直到所选的 bundle throughput 和大于 minimumThroughputToOffload,返回所选的 bundle
基于最大物理资源使用率的 shedding 算法一般表现不算太好,原因有多个:
- 算法只考虑多项资源的最大值,而不同的物理资源可能会有较大波动,比如 CPU 和 内存
- loadBalancerBrokerOverloadedThresholdPercentage 配置比较难去合理调整,配置太小,会导致频繁卸载;配置太大,会导致长时间不卸载,都很难达到均衡的状态
2.3.2 ThresholdShedder
OverloadShedder 算法没有考量集群中 broker 的实际负载信息,而是直接根据物理资源使用率来作为卸载的依据;针对这个问题,ThresholdShedder 做出了改进,ThresholdShedder 也是基于物理资源的一种算法,但是 ThresholdShedder 可以为各项资源使用率配置权重,并且会根据整体集群的平均负载来做决策,而不是根据一个上限来卸载。
首先,会计算所有 broker 的平均负载,根据 broker 上报信息,计算最大物理资源使用率(考虑权重)
double resourceUsage = localBrokerData.getMaxResourceUsageWithWeight(
conf.getLoadBalancerCPUResourceWeight(),
conf.getLoadBalancerDirectMemoryResourceWeight(),
conf.getLoadBalancerBandwithInResourceWeight(),
conf.getLoadBalancerBandwithOutResourceWeight());
得到的各项资源乘上权重之后的最大值,除此之外也会考虑历史负载的占比,
historyUsage = historyUsage == null
? resourceUsage : historyUsage * historyPercentage + (1 - historyPercentage) * resourceUsage;
各个配置项如下:
# 资源权重占比,默认都是 1.0
loadBalancerCPUResourceWeight=1.0
loadBalancerDirectMemoryResourceWeight=1.0
loadBalancerBandwithInResourceWeight=1.0
loadBalancerBandwithOutResourceWeight=1.0
# 历史负载的占比,默认是 0.9,负载计算时,越小当前负载会越快生效,反之则当前负载会越慢的起作用
loadBalancerHistoryResourcePercentage=0.9
计算出每个 broker 的负载之后,取平均值 avgUsage。
ThresholdShedder 是希望所有的 broker 的负载都能维持在 avgUsage 附近,因此会有一个参数表示距离 avgUsage 的差距,
# 表示负载均衡的上限限
# 满足条件 usageAvg - threshold <= brokerResourceUsage < usageAvg + threshold 的 broker 被认为处于均衡状态
loadBalancerBrokerThresholdShedderPercentage=10
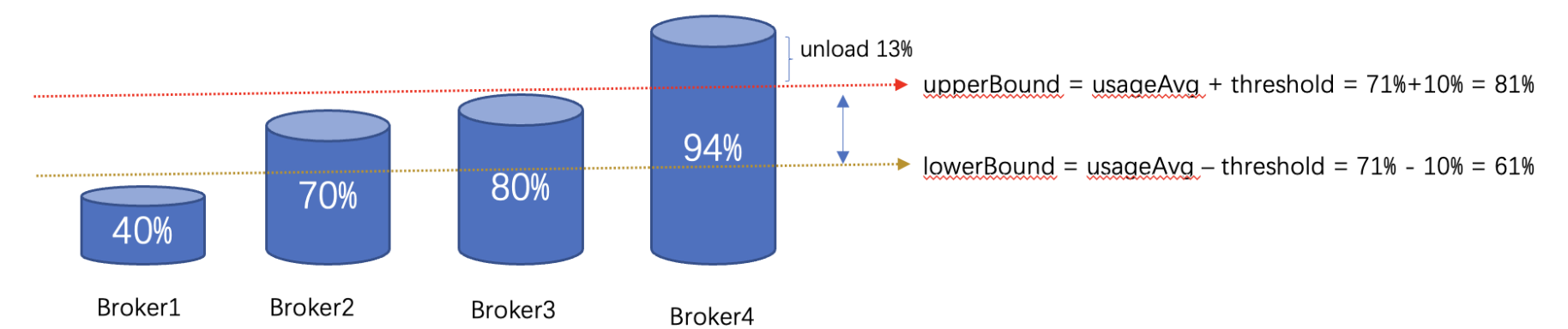
如图示: avgUsage 是 71, threshold 是 10,那么 broker2 和 broker3 是出于均衡状态的节点,Broker4 出于 overload 状态,broker1 出于低负载状态。
然后,查找 overload 的 broker,遍历 broker,负载超过 avgUsage + threshold 的 broker 被标记为 overload 。
为 overload 的节点计算写在的数据量
double percentOfTrafficToOffload =
currentUsage - avgUsage - threshold + ADDITIONAL_THRESHOLD_PERCENT_MARGIN;
double brokerCurrentThroughput = localData.getMsgThroughputIn() + localData.getMsgThroughputOut();
double minimumThroughputToOffload = brokerCurrentThroughput * percentOfTrafficToOffload;
计算逻辑如下:
- 计算卸载比例 percentOfTrafficToOffload :currentUsage - avgUsage - threshold + 0.05(5%)
- 计算 broker 吞吐 brokerCurrentThroughput:throughputIn + throughputOut
- 计算卸载量 minimumThroughputToOffload :percentOfTrafficToOffload * brokerCurrentThroughput
在查找卸载的 bundle 之前,还有一个校验,判断持此卸载的数量是否大于配置的最小卸载量
# 最小的卸载量,默认是 10 MB,如果小于该值,不执行卸载
loadBalancerBundleUnloadMinThroughputThreshold=10
接下来,选择卸载的bundle,这一步骤和 overload shedder 类似,也是遍历 broker 的所有 bundle 信息,按照 shortTermData 的 (throughputIn + throughputOut)排序(逆序),从 throughput 从大到小选择 bundle(会过滤掉最近 unload 的 bundle),直到所选的 bundle throughput 和大于 minimumThroughputToOffload,返回所选的 bundle。
这个过程可能没有选择到 bundle,ThresholdShedder 算法会有额外的处理,假如 lowerBoundarySheddingEnabled 配置开启,
# 低负载节点是否触发卸载,默认为 false,可以解决集群中出现节点低负载的问题,比如上图的 broker1、broker2、broker3 的状态
lowerBoundarySheddingEnabled=false
低负载节点(usage < avgUsage - threshold)卸载的流程如下:
- 选出计算集群中负载最高的节点
- 计算其吞吐 throughput:throughputIn + throughtputOut
- 计算卸载的量:throughput * threshold * 0.5
- 判断是否大于最小卸载量 loadBalancerBundleUnloadMinThroughputThreshold
- 最后选在需要卸载的 bundle
选择到需要卸载的 bundle 之后,需要为这些 bundle 选择卸载的 target broker,target broker 的选择在 2.4 节,这里不在展开。
最后通过 Pulsar Admin 执行 bundle 的卸载,卸载会指定 target broker,并且将 bundle 记录到 recentlyUnloadedBundles 中。
ThresholdShedder 算法也是基于物理资源使用率的一种 shedding 算法,不同的物理资源可能会有较大波动,比如 CPU 和 内存,如果是在混合部署的场景下,机器的物理资源并不能反应 broker 的实际负载信息。
2.3.3 UniformLoadShedder
UniformLoadShedder 是一种完全基于 broker 自身负载信息的卸载算法,从msgRate、msgThroughtput 两个维度来选择要写在的 broker 和 bundle。
其主要的思想是观察集群中负载最高的节点 maxUsageBroker 和 负载最低的绩点 minUsageBroker 之间的负载差异,这里会涉及到两个配置
# msgRate 的差异阈值,默认是 50
# msgRate差异 计算的是最高负载比最低负载高的百分比((max - min)/min * 100 )
loadBalancerMsgRateDifferenceShedderThreshold=50
# msgThroughput 的差异阈值,默认是 4
# msgThroughput 差异计算的是最高负载/最低负载的倍数(max/min)
loadBalancerMsgThroughputMultiplierDifferenceShedderThreshold=4
即同时满足这两个条件的 broker 被认为处于均衡状态
(maxMsgRate – minMsgRate) / minMsgRate * 100 <= loadBalancerMsgRateDifferenceShedderThreshold
maxThroughputRate / minThroughputRate) <= loadBalancerMsgThroughputMultiplierDifferenceShedderThreshold
首先,计算负载最高和最低的节点,遍历 loadData 中所有 broker,计算出最高和最低负载的 broker 的差异,然后计算 msgRate 和 msgThroughput 是否超过配置,如果超出限制,则会计算需要卸载的数据量,同样的,也会涉及到一个卸载百分比的配置
# 卸载的百分比,默认是 0.2
# 按照 msgRate 或者 msgThroughput 乘以这个系数得到需要卸载的数据量
maxUnloadPercentage=0.2
MutableInt msgRateRequiredFromUnloadedBundles = new MutableInt(
(int) ((maxMsgRate.getValue() - minMsgRate.getValue()) * conf.getMaxUnloadPercentage()));
MutableInt msgThroughputRequiredFromUnloadedBundles = new MutableInt(
(int) ((maxThroughputRate.getValue() - minThroughputRate.getValue())
* conf.getMaxUnloadPercentage()));
计算得到卸载 msgRate 和 msgThroughput 之后,判断是否超过最小的卸载阈值,
# msgRate 的最小卸载数据量,默认是 1000
minUnloadMessage=1000
# msgThroughput 的最小卸载数据量,默认是 1MB
minUnloadMessageThroughput=1*1024*1024
如果需要卸载的数据量大于最小卸载阈值,则可以继续选择卸载的 bundle。
接下来,就是选择卸载 bundle 的过程,遍历所有 bundle ,这一步骤和 overload shedder 类似,也是遍历 broker 的所有 bundle 信息,按照 shortTermData 的 排序(逆序),从 throughput 从大到小选择 bundle(会过滤掉最近 unload 的 bundle),直到选到足够的 bundle。
选取 bundle 的流程会有一个特殊的逻辑,因为有 msgRate 和 msgThroughput 两个维度,所以会有一个优先级的问题,目前的实现默认是以 msgRate 优先,即如果 msgRateExceed,则只计算 msgRate(否则才会计算 msgThroughput):
- 首选在遍历 bundle 负载时,就优先计算 shortTermData 的 msgRate 信息,并逆序排序
- 逐个选取 bundle,直到满足卸载量的需求
如果 msgRate 没有超过限制,则按照 msgThroughput 来计算,过程是类似的,不在赘述。
选择到需要卸载的 bundle 之后,需要为这些 bundle 选择卸载的 target broker,target broker 的选择在 2.4 节,这里不在展开。
最后通过 Pulsar Admin 执行 bundle 的卸载,卸载会指定 target broker,并且将 bundle 记录到 recentlyUnloadedBundles 中。
问题
- max 和 min 负载 broker 计算过程有 bug,会拿到不合理的 broker
- 其实默认是 msgRate 优先的一个算法,效果可能并不好
在选择需要 shedding 的 bundle 之后,首先会做 isolation 和 AntiAffinityNamespace 的校验,校验通过之后会为 bundle 选择放置的 broker。
2.4 bundle placement
2.3 节描述了 bundle shedding 的几种常用的算法,overload 的 broker 上 shedding 的 bundle 需要被分配到其他的低负载的 broker 节点上,才能实现负载均衡,如何为一个 bundle 选择放置的 target broker 就是 bundle placement 策略做的事情。
遍历所有需要卸载的 bundle,为每个 bundle 选在一个目标 broker。
- 遍历所有 available 的 broker,按照 isolation 配置将 broker 加入备选集合
- 应用 isolation 策略,过滤一部分 broker 节点
- 过滤掉 topic 数量太多的 broker,默认配置为
loadBalancerBrokerMaxTopics(50000) - 应用 anti-affinity-group 策略,过滤一部分 broker
过滤掉一些 broker 知乎, target broker 的选择主要 依赖于 ModularLoadManagerStrategy 的 算法如何选择,目前有三种算法:
- RoundRobinBrokerSelector
- LeastLongTermMessageRate
- LeastResourceUsageWithWeight
默认的 placement strategy 是 LeastResourceUsageWithWeight,
2.4.1 RoundRobinBrokerSelector
最简单的方案就是轮询,把所有可选的 broker 作为一个列表,按照递增的顺序选择下一个 broker。
2.4.2 LeastResourceUsageWithWeight
通过名字看,这个放置策略和 ThresholdShedder 是比较匹配的,都是考虑了物理资源的使用率,并且可以配置多项物理资源的权重。
遍历所有的 broker 候选,计算 broker 的最大资源使用率,计算方式和 ThresholdShedder 方式类似,也会考虑历史负载的占比。
- 计算每个 broker 的负载,保存,并且计算所有 broker 的总体负载
- 计算每个 broker 的 avgUsage 负载信息
选取目标 broker 需要从比 avgUsage 负载的低的 broker 中来选择,并且为了防止频繁卸载,会选择比 avgUsage 负载低一定量的 broker 中来选择,具体配置项是:
# 选择目标 broker 时,比 avgUsage 低这么多的 broker 才会作为备选
loadBalancerAverageResourceUsageDifferenceThresholdPercentage=10
选取到一批 broker 作为备选之后,从中随机选择一个作为 target broker。
2.4.3 LeastLongTermMessageRate
LeastLongTermMessageRate 算法会根据 bundle 和 broker 的 longTerm 负载信息来选择低负载的节点来作为 target broker。
遍历 broker 列表中每一个 broker,计算每个 broker 的分数,原理就是累加所有 bundle 和 broker 的 longTerm 的 msgRate 信息:
- 遍历所有 bundle 信息,累加 longTerm 数据中的 msgRateIn + msgRateOut
- 累加 brokerData 中 longTerm 数据中的 msgRateIn + msgRateOut
记录分数最低(负载最低的)节点,可能会有多个,如果有多个随机从中选择一个。
2.5 bundle split
bundle split 的作用是针对负载较高的 bundle 做切分,在有 broker 负载变更之后,会回调 udpateAll,最后的步骤会检查是否执行 bundle 的 split。
另外,bundle split 可以已通过 admin 工具来操作。
执行 bundleSplit ,bundleSplit 有几个必要的前提:
- split 开关打开: 配置项是
loadBalancerAutoBundleSplitEnabled - 必须是 leader 节点
- broker 节点数大于 1
如果条件都满足,则根据 split 的条件来检查需要执行bundle split 操作 bundle,
# namespace 的最大 bundle 数,默认是 128,超过这个上限时,不会继续 split bundle
loadBalancerNamespaceMaximumBundles=128
# bundle 最大 topic 数量,超过这个限制,可以执行 split
loadBalancerNamespaceBundleMaxTopics=1000
# bundle 最大 session 数量(producer + consumer),默认是 1000,超过可以执行 split
loadBalancerNamespaceBundleMaxSessions
# bundle 的最大 msgRate(in+out),默认是 30000,超过可以执行 split
loadBalancerNamespaceBundleMaxMsgRate=30000
# bundle 的最大 msgThroughput,默认是 100MB,超过可以执行 split
loadBalancerNamespaceBundleMaxBandwidthMbytes=100
loadData 中的 brokerData 和 bundleData 信息已经更新,遍历所有 broker 的 lastStats 的所有 bundle
- 跳过 topic 数量小于 2 的 bundle
- 对于每个 bundle,从 bundleData 中取出 longTermData,获取 longTermdata 的 msgRate 和 msgThroughtput
- 满足以下条件之一可以执行 split
- Topic 数量 > loadBalancerNamespaceBundleMaxTopics
- loadBalancerNamespaceBundleMaxSessions > 0, 并且 bundle 的 producer + consumer 数量 > loadBalancerNamespaceBundleMaxSessions
- msgRate > loadBalancerNamespaceBundleMaxMsgRate
- msgThroughtput > loadBalancerNamespaceBundleMaxBandwidthMbytes
执行 split 之前要判断 bundle 数量是否超过 loadBalancerNamespaceMaximumBundles,超过不会继续 split,不超过才会执行 split 操作,因为这个过程中会检查多个 bundle 是否需要执行 split,因此在完成检查之前,会记录需要 split 的 bundle 信息,来避免多个 bundle 的 split 导致最终的 bundle 数量超过 loadBalancerNamespaceMaximumBundles。
至此,就拿到了需要执行 split 的 bundles 信息,下面来看如何执行 split 操作,对于一个需要 split 的 bundle:
- 首先判断 bundle 上下限是否满足切分条件,upperBound > lowerBound + 1
- 从 loadData 的 bundleData 中移除 bundle 信息,避免 bundle 再次被选中
- 从当前 broker 的 localData 中移除 bundle 信息
- 从 bundleCache 中,让 bundle 缓存失效,以便 split 之后加载最新的 bundle 信息到缓存中
- 从 zk 路径
/loadbalance/bundle-data/teantn/ns/$bundle下删除 bundle 数据 - 判断切分之后的 bundle 是否需要 unload
- 配置项为
loadBalancerAutoUnloadSplitBundlesEnabled - 另外也会受到 isolation 以及 namesapce 亲密性配置影响
- 配置项为
- 调用 admin 命令执行 bundle 的 split 操作
Broker 接收到 bundle split 请求之后的处理逻辑如下:
- 权限校验
- 检验 split 算法,支持的算法包括四种:参数为
supportedNamespaceBundleSplitAlgorithms- "range_equally_divide"
- "topic_count_equally_divide"
- "specified_positions_divide"
- "flow_or_qps_equally_divide"
- 检验 namespace 的 ownerShip,会重定向到目标集群
- 校验是否只读,只读则不允许操作
- 校验 namespace bundle 的 ownership
- 开始执行 bundle split,切分的行为和具体的 split 算法相关,切分之后,可能是多个也可能是两个 bundle,切分算法会计算出 split 的 boundaries 信息,根据新的 boundaries 就可以计算出新的 bundle 信息
目前支持的 split 算法有四种:
- range_equally_divide
- topic_count_equally_divide
- specified_positions_divide
- flow_or_qps_equally_divide
2.5.1 range_equally_divide
从 bundle 的 hash 中间位置切分
2.5.2 topic_count_equally_divide
从 topic 数量的中间位置切分
2.5.3 specified_positions_divide
根据指定的位置切分,需要优先获取 position 位置, position 可以通过 GetTopicHashPositions 命令来获取 bundle 上指定 topic(partition)或者所有 topoic 的 position,根据这些 position 信息,决定切分的位置,然后根据这些位置进行切分。
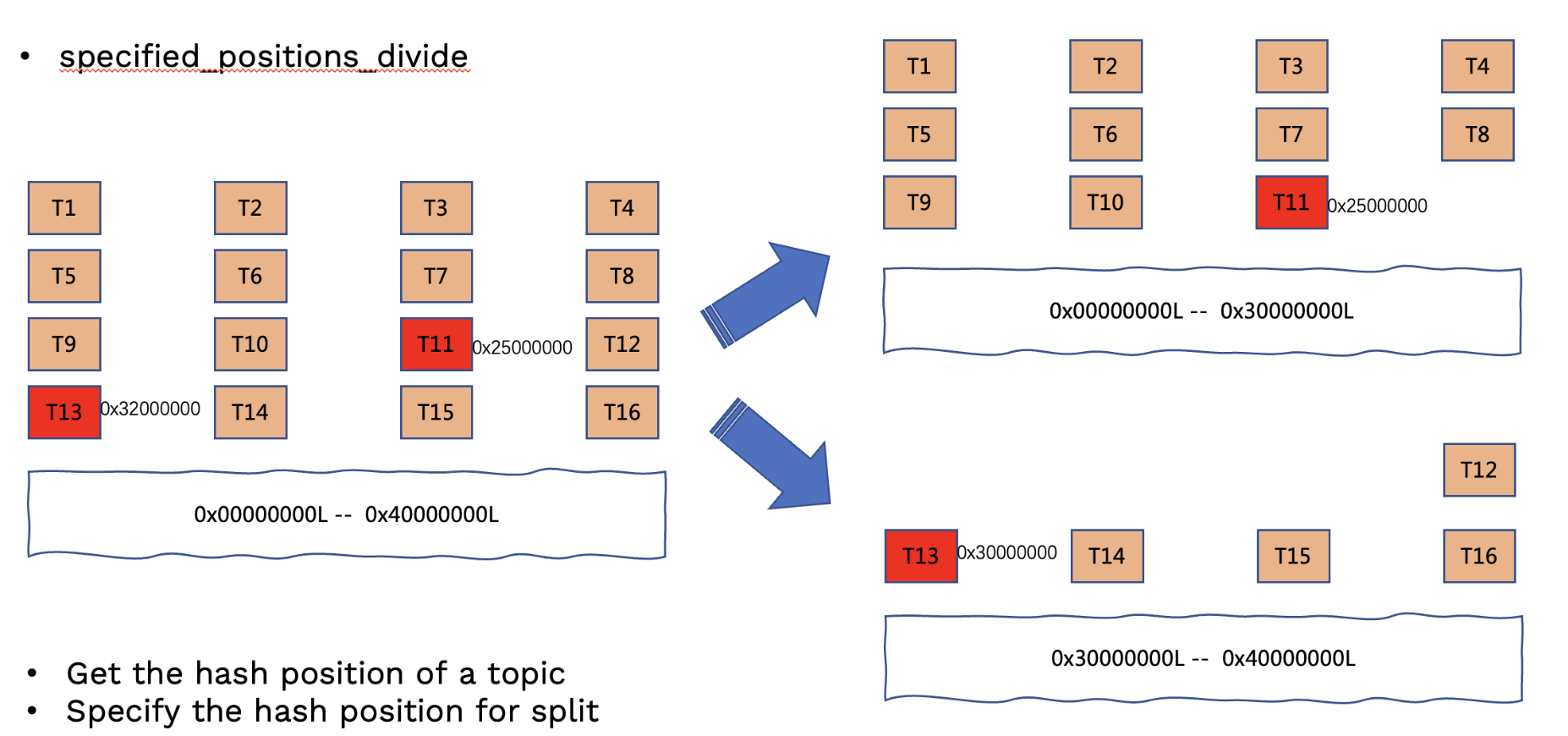
一个典型的应用场景:在一个存在大量 topic 的 bundle 上有个别分区流量很高,其他都很低,这时候可以根据高流量分区的 position 进行切分。
2.5.4 flow_or_qps_equally_divide
这个算法实际上是根据 msgRate 或者 msgThroughput 来切分 bundle 的,涉及到三个核心参数:
# 单个 bundle 上的最大 msgRate(in+out),默认是 3 w
loadBalancerNamespaceBundleMaxMsgRate=30000
# 单个 bundle 上的最大 msgThroughtput(in+out),默认是 100 MB
loadBalancerNamespaceBundleMaxBandwidthMbytes=100
# 切分的时的上浮百分比,默认是 10%, 即当
# 1. msgRate > (100+flowOrQpsDifferenceThresholdPercentage)/100*loadBalancerNamespaceBundleMaxMsgRate 或者
# 2. msgThroughtput >
# (100+flowOrQpsDifferenceThresholdPercentage) /100 * loadBalancerNamespaceBundleMaxBandwidthMbytes 时
# 执行 split bundle 操作
flowOrQpsDifferenceThresholdPercentage=10
简单来讲,这个算法会遍历 bundle 上所有的 topic,计算 topic 的 msgRate 和 Throughtput,每当累加的 msgRate 或者 Throughtput 超过配置值时,都会记录一个切分点,最终会按照配置的 msgRate 和 msgTHroughput 将 bundle 切分成多个。
在通过 split 算法获取到 splitBoundaries 之后
- 会构建出多个新 Bundle
- 当前 Broker 会尝试获取新 bundle 的 ownership
- 将新的 bundle 信息写入到 metaStore(localPolicy) 中
- 将新的 bundle 信息写入到 configurationStore (global policy)中
- 然后 NamespaceBundleFactory.bundlesCache 失效现有的 bundle(切分前的 bundle)
- 从 OwnershipCache.ownedBundlesCache 中将原 bundle 状态设置为 设为 inActive
- BrokerService.refreshTopicToStatsMaps
- 从 multiLayerTopicsMap 获取 bundle 下所有 topic,更新新的 bundle 到multiLayerTopicsMap
- 从 multiLayerTopicsMap 移除原 bundle 信息
- pulsarStats 删除原 bundle 信息
- 从 OwnershipCache 中移除原 bundle,OwnershipCache.removeOwnership
- 如果指明了 split 之后 unload,则对所有新的 bundle 进行 split
3. 如何分配 bundle 给 broker
在 客户端执行 lookup 时,实际上并不是分配的单个topic,而是分配的一个bundle,这样可以显著降低元数据的数量。
3.1 LookUp 命令
比如在执行 lookup 命令时,
CompletableFuture<Optional<LookupResult>> future = getBundleAsync(topic)
.thenCompose(bundle -> findBrokerServiceUrl(bundle, options));
这里主要执行两个操作,第一步是 获取 topic 所在的 bundle,第二步是查找 bundle 所在的 broker。
3.1.1获取 topic 所在的 bundle
查找 topic 所在 bundle 也分为两步,第一步是获取 namespace 的 bundle 信息,第二步是计算得到 topic 所在的 bundle
3.1.1.1 查找 namespace 的 bundle
首先 从 local-policies 中获取,/admin/local-policies/tenant/namespace 路径的内容,格式如下:
[zk: localhost:2181(CONNECTED) 18] get /bookie_ps_test/admin/local-policies/test/test
{"bundles":{"boundaries":["0x00000000","0x40000000","0x80000000","0xc0000000","0xffffffff"],"numBundles":4}}
如果找不到的话,则从 policies 去获取 /admin/policies/tenant/namespace 的内容,这里包含了namespace的全部policies信息,格式如下:
[zk: localhost:2181(CONNECTED) 19] get /pulsar_ps_test/admin/policies/test/test
{"auth_policies":{"namespace_auth":{},"destination_auth":{},"subscription_auth_roles":{}},"replication_clusters":["ps_test"],"bundles":{"boundaries":["0x00000000","0x40000000","0x80000000","0xc0000000","0xffffffff"],"numBundles":4},"backlog_quota_map":{"destination_storage":{"limit":-1073741824,"policy":"producer_request_hold"}},"clusterDispatchRate":{},"topicDispatchRate":{"ps_test":{"dispatchThrottlingRateInMsg":0,"dispatchThrottlingRateInByte":0,"relativeToPublishRate":false,"ratePeriodInSecond":1}},"subscriptionDispatchRate":{"ps_test":{"dispatchThrottlingRateInMsg":0,"dispatchThrottlingRateInByte":0,"relativeToPublishRate":false,"ratePeriodInSecond":1}},"replicatorDispatchRate":{},"clusterSubscribeRate":{"ps_test":{"subscribeThrottlingRatePerConsumer":0,"ratePeriodInSecond":30}},"persistence":{"bookkeeperEnsemble":3,"bookkeeperWriteQuorum":2,"bookkeeperAckQuorum":2,"managedLedgerMaxMarkDeleteRate":0.0},"publishMaxMessageRate":{},"latency_stats_sample_rate":{},"message_ttl_in_seconds":36000,"deleted":false,"encryption_required":false,"subscription_auth_mode":"None","max_producers_per_topic":0,"max_consumers_per_topic":0,"max_consumers_per_subscription":0,"max_unacked_messages_per_consumer":50000,"max_unacked_messages_per_subscription":200000,"compaction_threshold":0,"offload_threshold":-1,"schema_auto_update_compatibility_strategy":"Full","schema_compatibility_strategy":"UNDEFINED","is_allow_auto_update_schema":true,"schema_validation_enforced":false}
然后从这个policies中获取 bundles 信息,根据这个信息构造一个新的 LocalPolicies,并且更新到zk。完成之后,在bundlecache中也就具有了这个 bundle 信息。
得到所有的bundle 信息之后,根据 topic的hashCode,看topic落在哪个bundle 方位内,这个bundle 就是topic所在的bundle。
3.1.2 查找 bundle 所在的brokerUrl
-
首先检查 ownerShipCache 中有没有这个 bundle 信息,如果有直接返回;
-
没有则继续查找,这个查找的过程就是 bundle 的分配过程,
searchForCandidateBroker(bundle, future, options);
- 先排除掉 heartbeat 和 sla namespace,我们只看正常的 namespace bundle 的查找,如果查找options中已经指定了当前broker为bundle的owner,直接返回当前broker的url信息;
- 否则继续查找,首先找到当前leader,作为执行负载均衡决定的节点,如果当前节点是leader 或者当前 ledger 不是 active 状态,则在当前节点做分配,这时会为bundle查找负载最低的broker节点
- 从 LoadData 的 bundle 信息找,查找
- 如果当前节点不是leader节点,并且leader节点是active,则会重定向到 leader节点
附录
1. 负载均衡参数
# 负载均衡总开关,默认为 true,如果设置为 false,所有的负载任务都不会执行
loadBalancerEnabled=true
# 负载上报任务相关配置 start #
## 每个 broker 节点负载计算任务周期,并不一定会更新 zk,需要判断负载变化程度决定是否实际上报到 zk
loadBalancerReportUpdateMinIntervalMillis=5000
## bundle stats 信息更新时间,默认是一分钟,实际上是 pulsarStats 的更新周期
statsUpdateInitialDelayInSecs=60
## 负载变化百分比,默认是 10%, 超过这个则会执行上报:包括系统资源,msgRate,msgThroughtput,bundle 数
loadBalancerReportUpdateThresholdPercentage=10
## 最大上报时间间隔,默认是 15 分钟,超过则执行上报
loadBalancerReportUpdateMaxIntervalMinutes=15
# 负载上报任务相关配置 end #
# 负载汇总、更新相关配置 start #
## 负载更新到 zk 的周期,默认是 15 分钟(负载更新到本地由 zk `/loadbalance/brokers` 路径下内容发生变动时,回调触发全量更新 )
loadBalancerResourceQuotaUpdateIntervalMinutes=15
# 负载汇总、更新相关配置 end #
# bundle shedding相关配置 (uniform)start #
# leadger 执行 bundle shedding 任务的周期,默认是 1 分钟
loadBalancerSheddingIntervalMinutes=1
# msgRate 的差异阈值,默认是 50,msgRate差异 计算的是最高负载比最低负载高的百分比((max - min)/min * 100 )
loadBalancerMsgRateDifferenceShedderThreshold=50
# msgThroughput 的差异阈值,默认是 4, msgThroughput 差异计算的是最高负载/最低负载的倍数(max/min)
loadBalancerMsgThroughputMultiplierDifferenceShedderThreshold=4
# msgRate 的最小卸载数据量,默认是 1000
minUnloadMessage=1000
# msgThroughput 的最小卸载数据量,默认是 1MB
minUnloadMessageThroughput=1*1024*1024
# 一次 unload 最多卸载的 bundle 数量
getMaxUnloadBundleNumPerShedding=-1
# 做大的卸载占比,卸载差异值的占比,默认是 0.2
maxUnloadPercentage= 0.2
# bundle unload 之后的保护时间,不会频繁的 unload
loadBalancerSheddingGracePeriodMinutes=30
# bundle shedding相关配置 end #
# bundle placement 相关配置 start #
## 计算物理资源使用率时的历史负载占比,即 historyUsage * 0.9 * currentUsage * 0.1
loadBalancerHistoryResourcePercentage=0.9
## LeastLongTermMessageRate 算法配置 start ##
## overload broker 的物理资源使用阈值,计算 overload broker 时不考虑资源权重,overload 的 broker 不会优先作为备选节点,只有当集群汇总所有节点都处于 overload 时才会作为备选
loadBalancerBrokerOverloadedThresholdPercentage=85
## LeastLongTermMessageRate 算法配置 end ##
## LeastResourceUsageWithWeight 算法配置 start ##
# 选择目标 broker 时,比 avgUsage 低这么多的 broker 才会作为备选节点,计算 broker 负载 时会考虑资源权重
loadBalancerAverageResourceUsageDifferenceThresholdPercentage=10
## LeastResourceUsageWithWeight 算法配置 end ##
# bundle placement 相关配置 end #
# bundle split 相关配置 start #
## 是否开启自动的 bundle split,默认是 true
loadBalancerAutoBundleSplitEnabled=true
## split 的 bundle 是否自动 unload
loadBalancerAutoUnloadSplitBundlesEnabled=true
## namespace 的最大 bundle 数,默认是 128,超过这个上限时,不会继续 split bundle
loadBalancerNamespaceMaximumBundles=128
## bundle 最大 topic 数量,超过这个限制,可以执行 split
loadBalancerNamespaceBundleMaxTopics=1000
## bundle 最大 session 数量(producer + consumer),默认是 1000,超过可以执行 split
loadBalancerNamespaceBundleMaxSessions
## bundle 的最大 msgRate(in+out),默认是 30000,超过可以执行 split
loadBalancerNamespaceBundleMaxMsgRate=30000
## bundle 的最大 msgThroughput,默认是 100MB,超过可以执行 split
loadBalancerNamespaceBundleMaxBandwidthMbytes=100
## 支持的 split 的算法
supportedNamespaceBundleSplitAlgorithms=range_equally_divide,topic_count_equally_divide,specified_positions_divide
## 默认的 split 算法
defaultNamespaceBundleSplitAlgorithm=range_equally_divide
# bundle split 相关配置 end #
2. 推荐配置
线上环境 broker 和 bookie 混合部署,因此使用物理资源相关的算法效果可能会不好,因此推荐使用 uniform shedder 算法,并且被屏蔽掉物理资源的影响。
# 负载均衡总开关
loadBalancerEnabled=true
# 负载汇总、更新相关配置 start #
## 负载更新到 zk 的周期,默认是 15 分钟(负载更新到本地由 zk `/loadbalance/brokers` 路径下内容发生变动时,回调触发全量更新 )
loadBalancerResourceQuotaUpdateIntervalMinutes=10
# 负载汇总、更新相关配置 end #
# bundle shedding相关配置 (uniform)start #
# msgRate 的差异阈值,默认是 50,msgRate差异 计算的是最高负载比最低负载高的百分比((max - min)/min * 100 )
loadBalancerMsgRateDifferenceShedderThreshold=50
# msgThroughput 的差异阈值,默认是 4, msgThroughput 差异计算的是最高负载/最低负载的倍数(max/min)
loadBalancerMsgThroughputMultiplierDifferenceShedderThreshold=4
# 一次 unload 最多卸载的 bundle 数量
getMaxUnloadBundleNumPerShedding=5
# 最大的卸载占比,卸载差异值的占比
maxUnloadPercentage= 0.5
# bundle shedding相关配置 end #
## LeastLongTermMessageRate 算法配置 start ##
## overload broker 的物理资源使用阈值,计算 overload broker 时不考虑资源权重,overload 的 broker 不会优先作为备选节点,只有当集群汇总所有节点都处于 overload 时才会作为备选
loadBalancerBrokerOverloadedThresholdPercentage=120
## LeastLongTermMessageRate 算法配置 end ##
# bundle split 相关配置 start #
## 开启 bundle 自动 split
loadBalancerAutoBundleSplitEnabled=true
## 关闭 bundle split 之后的自动 bunload
loadBalancerAutoUnloadSplitBundlesEnabled=false
## namespace 的最大 bundle 数 512
loadBalancerNamespaceMaximumBundles=512
## bundle 最多 100 个 topic
loadBalancerNamespaceBundleMaxTopics=100
## bundle 最多 1000 个(producer + consumer)
loadBalancerNamespaceBundleMaxSessions=1000
## bundle 的最大 msgRate(in+out)为 10000
loadBalancerNamespaceBundleMaxMsgRate=10000
## bundle 的最大 msgThroughput,默认是 100 MB,超过可以执行 split
loadBalancerNamespaceBundleMaxBandwidthMbytes=100
## 支持的 split 的算法
supportedNamespaceBundleSplitAlgorithms=range_equally_divide,topic_count_equally_divide,specified_positions_divide,flow_or_qps_equally_divide
## 默认的 split 算法
defaultNamespaceBundleSplitAlgorithm=flow_or_qps_equally_divide
# bundle split 相关配置 end #